Release Control:
When launching a product "in the wild" require to know what you release, which & when. This may seem trivial, but in a great development environment can be complicated.Take, for example, a method where ten developers are working in parallel on a piece of code. When you will build & launch a version of the method, how to know what changes have been checked? By releasing multiple versions of the same method to multiple clients & start to document bugs, three months later, how do you know which version the error occurs in?How to know which version to upgrade to solve the problem? Hopefully your version control method have been described as every component of your code with a one-of-a-kind identifier when a customer contacts you, you can reverse the source version
method select which version they have.Besides its exchange control method will permit you to identify the changes for that version of the method so that you can identify the cause of the problem & correct it. Their control method changes You must also register the product version that contains the revision & therefore you can update all clients on the correct version.Normally, you ought to track the following items for each version:
• The version number of the release
• The date of release
• The purpose of the release (maintenance, bug fixes, tests, etc.)
• For each program component within the release:
• the name & version number of the component
• the date it was last modified
• any type of control that confirms the integrity of each module
Controls the release should be applied in development as well as abroad. When the development team press a product to the check team, you must follow a controlled technique. This ensures that teams are working on the same underlying product defects that are being tracked & resolved against a particular, the construction & that there is minimal delay in the resolution of defects.
Verification and Smoke Testing:
An important part of the monitoring method of liberation is to verify the basic functionality of a particular release. Often, errors in construction, assembly or compilation method can lead to errors in given release. Spending time to identify & isolate these faults is frustrating & pointless because they are basically objects of poor construction.A statement should be checked for basic functionality by using "smoke tests". That is, before is passed to any other group, the team responsible for building a release must execute a series of simple tests to decide that the release is working properly. This catch gross malfunctions quickly & avoid any delay in releases. These tests can be automated under construction / release method & the results basically checks before the release is sent.Smoke testing The term comes from the electronics industry. If an engineer designs a circuit or electrical process of the first check to do is connect the power briefly & turn it on. If the smoke comes out then you switch it off & return to the drawing board (or solder). smoke appears then is fundamentally nice & you can try some more tests on it to see if working properly. The same principle can be applied in program development.
A statement must be verified to complete well.Often, emissions can be built without a database or configuration file that is necessary. Part of
the release method should be a simple check that verifies that all components are expected present in a statement. This can be completed by maintaining a separate list of components needed which can be automatically against an individual building to decide if something is missing.
Release Notes:
A very valuable piece of documentation that is often forgotten in the projects is a set of release notes. Accompanying each version should be a short series of notes that details (in plain English) changes in the technique or product with this release.The main reason for the inclusion of release notes is to help set expectations with finish users. By including a list of "known issues" with a particular release can focus attention on important areas of the release and keep the same number reported again and again.If the release is a Beta version of tester / clients of the notes may also include some notes on how finish users can expect voting record and what type of information to be provided. If the release is a version of normal production, then the notes should be more formal and legal hold and the license information and information on how to contact support.
Release Notes: APR SDK v3.0.5.29
Scope of delivery
This press release picture file contains four separate file:
documentation file - this file contains all the necessary architecture and
installation documentation for the SDK.
SDK installation file - This file is intended to be installed by users who need a
desktop version of the application.
SDK binaries - an executable file that contains only the 'parts of the SDK
This file is intended for people who intend to integrate the SDK in to an application.
Known Issues
1. Threadpool varying sizes of the pool through the registry is not enabled
An interim multi-threading model used a series of adjustments in a registry key to permit for changes in be made to the number of threads obtainable for the SDK. These settings are no longer used and configuration threading model is set in the SDK.
2. Removing ABR.DLL
Some functionality pre-processor was contained in a separate DLL for historical reasons --
ABE DLL file \.
T e s t R e p o r t i n g a n d M e t r i c s
Software Defect Reports:
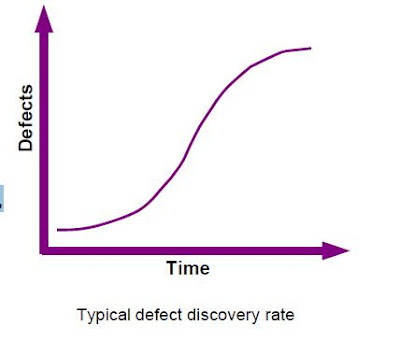
Reports of a basic defect level are simple:number of defects by the state & severity.Something like the diagram on the right.This shows the number of defects & their been in evidence. As the project progresses wait to see the marching through the graph from left to right - moving again to open a closed fixed.More complicated are reports of defects work possible. For example, you might require have a document on aging defects - How long were deficiencies in a particular state. This allows you to target the defects that have not advanced, they have not changed state for a period of time. Looking at the average age of defects in each state can predict how long number of defects will be fixed.By far the best document default is the default state trend as a graphic. This shows the total number of defects by the state in time (see below).The great advantage of this graph is that it allows predict the future. If you take the graph of theSeptember & draw a line down curve of the 'fixed' defects --cuts the x-axis after the final December. This means that since September,was not possible to predict all defects would be fixed in December & the project not finish on time. Similarly it follows the curve of the "new" defects that can intuit something about the progress of your project.If the peak in the curve is flat, & then, then you have a problem in development - the errors are not
remain fixed. Either the developers are the reintroduction of errors when trying to solve this problem, its
Code control is poor or there is another key issue.Time to get out the microscope.


Reports of a basic defect level are simple:number of defects by the state & severity.Something like the diagram on the right.This shows the number of defects & their been in evidence. As the project progresses wait to see the marching through the graph from left to right - moving again to open a closed fixed.More complicated are reports of defects work possible. For example, you might require have a document on aging defects - How long were deficiencies in a particular state. This allows you to target the defects that have not advanced, they have not changed state for a period of time. Looking at the average age of defects in each state can predict how long number of defects will be fixed.By far the best document default is the default state trend as a graphic. This shows the total number of defects by the state in time (see below).The great advantage of this graph is that it allows predict the future. If you take the graph of theSeptember & draw a line down curve of the 'fixed' defects --cuts the x-axis after the final December. This means that since September,was not possible to predict all defects would be fixed in December & the project not finish on time. Similarly it follows the curve of the "new" defects that can intuit something about the progress of your project.If the peak in the curve is flat, & then, then you have a problem in development - the errors are not
remain fixed. Either the developers are the reintroduction of errors when trying to solve this problem, its
Code control is poor or there is another key issue.Time to get out the microscope.


Root Cause Analysis:
Root cause analysis is to identify the cause of a defect.Basic root cause analysis can often be enlightening - if 50% of program defects are directly attributable to the requirements of the poor then you know you require to fix your requirements specification system. Moreover, if all I know is that your client is not happy with the product quality, then you have to do a lot of digging to discover the answer.To perform root cause analysis you require to be able to grasp the cause of each defect. This is the usually done by providing an arena in the tracking system defects that can be used to classify the cause of each failure (which decides what is the root cause could be a point of contention!)
Sub-classifications are possible, depending on the level of detail you need to go. To Eg what kind of condition the errors are occurring? Are requirements changing development? Are they incomplete? Are incorrect?Two time you have this information they can quantify the proportion of defects attributable to each cause.In this table, 32% of defects are attributable to mistakes made by the check team, a massive proportion.While it is clear that there's problems with
requirements, coding & configuration,giant number of errors of proof means that there major problems with the accuracy of the tests.While most of these defects will be rejected & closed, a considerable amount of time spent the diagnosis & debating them.This table can be broken down by the absence of other attributes such as "state" & "gravity".You can find for example that "high" severity defects are attributable to coding errors, but "low" severity defects are related configuration.A fuller analysis can be done by identifying the cause (as before) & how defect was identified. This can be a classification of the phase in which the defect is identified (design, unit check, technique check, etc.) or a more detailed analysis of the system used to discovered the defect (tutorial, code inspection, automated testing, etc.) This then gives a overview of the defect & how it is detected to help choose what of their strategies for eliminating defects are most effective.
requirements, coding & configuration,giant number of errors of proof means that there major problems with the accuracy of the tests.While most of these defects will be rejected & closed, a considerable amount of time spent the diagnosis & debating them.This table can be broken down by the absence of other attributes such as "state" & "gravity".You can find for example that "high" severity defects are attributable to coding errors, but "low" severity defects are related configuration.A fuller analysis can be done by identifying the cause (as before) & how defect was identified. This can be a classification of the phase in which the defect is identified (design, unit check, technique check, etc.) or a more detailed analysis of the system used to discovered the defect (tutorial, code inspection, automated testing, etc.) This then gives a overview of the defect & how it is detected to help choose what of their strategies for eliminating defects are most effective.
Metrics:
The maximum length for information capture & analysis is the use of comparative indicators.Metrics (theoretically) permit for the completion of the development cycle as a whole to be measured. To tell business decisions & method & permit development teams to implement method improvements or tailor their development strategies.The measurements are notoriously controversial, however.Provide figures only for complex processes such as program development can over-simplify things.There may be very valid reasons for program development with more defects other. Finding a comparative measure is often difficult & focus on a single standard of measurement, without understanding the complexity underlying risks to ill-informed interpretations.Most indicators focus on measuring the performance of a method or an organization. There has realized strong in recent years that the metric should be useful for individuals.The effectiveness of a method depends directly on the effectiveness of individuals within the method. The personal use of metrics at all levels of program development allows individuals to adjust habits toward more effective behaviors.
Testing Metrics for Developers:
If the aim of developers is the production of code, then a measure of their effectiveness is how well that code works. The converse of this is how buggy a particular piece of code is - the more defects,the less effective the code.A veteran of quality metrics is often to the fore is "defects per thousand lines of code" or"Defects by Kloc" (also known as the density of defects). This is the total number of defects divided by in the number of thousands of lines of code in the program under check.The problem is that each programming paradigm, the defects by Kloc becomes unstable. In the procedural languages of age the number of lines of code was reasonably proportionate. With the the introduction of development methodologies, object-oriented program that reuse of code blocks,the order will become largely irrelevant. The number of lines of code in a procedural language like C or Pascal, is not related to a new language like Java o. NET.The substitution of "defects / Kloc" is "a developer of defects per hour" or "defect injection rate.Program development larger or more complex requiring more time for developers to code and build.The number of defects injected a developer in their code during development is a direct
measure of code quality. The more defects, the poorer the quality. By dividing the the number of defects by the total hours devoted to the development to get a comparative measure of quality of different program development.
Defect injection = number of defects created/time scheduled
Note that this is not a measure of efficiency, quality only. A programmer who takes longer and isintroduce fewer defects more care than five that is sloppy and rushed. But how long is long? If a developer is only a bug-free piece of program a year, is that long? The Using a metric must be balanced by others to ensure that a balanced scorecard is used.Otherwise, it could be the manipulation of a dimension to the exclusion of all others Developing efficiency measures are beyond the scope of this text.
measure of code quality. The more defects, the poorer the quality. By dividing the the number of defects by the total hours devoted to the development to get a comparative measure of quality of different program development.
Defect injection = number of defects created/time scheduled
Note that this is not a measure of efficiency, quality only. A programmer who takes longer and isintroduce fewer defects more care than five that is sloppy and rushed. But how long is long? If a developer is only a bug-free piece of program a year, is that long? The Using a metric must be balanced by others to ensure that a balanced scorecard is used.Otherwise, it could be the manipulation of a dimension to the exclusion of all others Developing efficiency measures are beyond the scope of this text.
Test Metrics for Testers:
An obvious measure of the effectiveness of the check is how lots of defects are found - the more the better.But this is a comparative measure.You can measure the defects of a particular check phase as a proportion of total the number of defects in the product. The higher the percentage the more effective check. But how lots of defects in the product at any given time? If each phase presents more defects, this is a moving target. & how long you expect your customers to find all the defects you missed in testing? A month? A year? & let developers write programs that have small or no fault? This means that found small or no defects. Does that mean that your check is not effective? Probably not, basically fewer defects to find that a product of poor application.In lieu, you can measure the performance of individual testers.In a script 'heavy' environmental measures of the efficiency check are easily met. The number of check
cases or scripts of a tester is prepared in an hour might be considered a measure of its productivity during preparation. Also, the total number of people executed during the day can be considered a measure of efficiency in the execution of the check.But is it ?Consider a light script, or else the script environment. These testers do not script their cases so how can to measure their efficiency? Does this mean that can not be efficient? I would say they can.What if the evidence does not find fault? Are they effective, no matter how you write?Let us return to the effects of the tests - to identify & eliminate application defects That being the case, a gauge of efficiency of finding & removing defects faster than an inefficient process four. The number of check cases is not relevant. If you can eliminate lots of defects, no scripts,then the time of the scripts would be better used carrying out the tests, not write them.So the time to find a defect is a direct measure of the effectiveness of testing.Measurement of the shortcomings of this individual can be difficult. The total time involved in finding a fault cannot be apparent unless individuals keep close track of time spent in testing particular functions. In the script of heavy environments should also take in to account the time Scripting of a particular defect, which is another complication.But to measure this hard work by a particular check is easy - basically divide the total number of hours passed the check by the total number of defects recorded (recall to include preparation time).
Defect Discovery Rate = Number of defects found check hours
Note that you ought to only count those defects that are fixed in these equations.Why?New defects that have not been validated are not defects. Defects which are rejected are also defects. A flaw has been fixed, it is definitely a mistake to be corrected. If you have the wrong numbers, come to the wrongconclusions.
cases or scripts of a tester is prepared in an hour might be considered a measure of its productivity during preparation. Also, the total number of people executed during the day can be considered a measure of efficiency in the execution of the check.But is it ?Consider a light script, or else the script environment. These testers do not script their cases so how can to measure their efficiency? Does this mean that can not be efficient? I would say they can.What if the evidence does not find fault? Are they effective, no matter how you write?Let us return to the effects of the tests - to identify & eliminate application defects That being the case, a gauge of efficiency of finding & removing defects faster than an inefficient process four. The number of check cases is not relevant. If you can eliminate lots of defects, no scripts,then the time of the scripts would be better used carrying out the tests, not write them.So the time to find a defect is a direct measure of the effectiveness of testing.Measurement of the shortcomings of this individual can be difficult. The total time involved in finding a fault cannot be apparent unless individuals keep close track of time spent in testing particular functions. In the script of heavy environments should also take in to account the time Scripting of a particular defect, which is another complication.But to measure this hard work by a particular check is easy - basically divide the total number of hours passed the check by the total number of defects recorded (recall to include preparation time).
Defect Discovery Rate = Number of defects found check hours
Note that you ought to only count those defects that are fixed in these equations.Why?New defects that have not been validated are not defects. Defects which are rejected are also defects. A flaw has been fixed, it is definitely a mistake to be corrected. If you have the wrong numbers, come to the wrongconclusions.
Other Metrics for Testing and Development:
as developers are responsible for the errors in your code, so that testers should be responsible for mistakes in its reporting of defects. A lot of time can be wasted by both the development & testing equipment to hunt down the poorly specified on deficiencies or defects that arise in error.So a measure of the effectiveness of evidence therefore becomes the number of reports rejected by default development. Of coursework, you ought to minimize this value, or use it as a proportion of defects in session & purpose of each check & the check team with an overall objective of 0% - no errors.You may also target other indicators such as response times to reports of defects.If a developer has much time to respond to a defect document can have the whole process up. If
take a long time to correct a defect of the same can happen. Testers can also sit on the defects,retest them & sustaining the project.But beware of using these measures prescriptive.Defects are funny beasts. Are inconsistent & erratic. No comparability. A "minor"absence of gravity may look like another, but might take ten times longer to diagnose & resolve.The idiosyncrasies of different application products & programming languages can make a kind of
defects more difficult to repair than the other.& although these probably will average in time, do you need to penalize a developer orTester since been fitted with all the difficult problems?Food for thought \.\.You are measuring the rate of injection of defects.You are measuring the rate of detection.
If you do this for a long time may have an idea of the injection rate of the "media" defect, & the'average detection' defect rate (per process, computer, whatever). So when a new projectcomes, you can try to predict what will happen.If the average injection rate of default is 0. 5 defects per hour of development, & the new project has 800 hours of development, six could reasonably expect 400 defects in the project. If the mean defect detection rate is 0.2 defects per hour tester, tester probably going to take 2000 hours to find all of them. Are you so long? What do you do?Numbers dashboard But beware - use these indicators as "to highlight potential problems but not hung up on them. They are indicative at best.Things alter, people alter, application changes.
So will their indicators.
take a long time to correct a defect of the same can happen. Testers can also sit on the defects,retest them & sustaining the project.But beware of using these measures prescriptive.Defects are funny beasts. Are inconsistent & erratic. No comparability. A "minor"absence of gravity may look like another, but might take ten times longer to diagnose & resolve.The idiosyncrasies of different application products & programming languages can make a kind of
defects more difficult to repair than the other.& although these probably will average in time, do you need to penalize a developer orTester since been fitted with all the difficult problems?Food for thought \.\.You are measuring the rate of injection of defects.You are measuring the rate of detection.
If you do this for a long time may have an idea of the injection rate of the "media" defect, & the'average detection' defect rate (per process, computer, whatever). So when a new projectcomes, you can try to predict what will happen.If the average injection rate of default is 0. 5 defects per hour of development, & the new project has 800 hours of development, six could reasonably expect 400 defects in the project. If the mean defect detection rate is 0.2 defects per hour tester, tester probably going to take 2000 hours to find all of them. Are you so long? What do you do?Numbers dashboard But beware - use these indicators as "to highlight potential problems but not hung up on them. They are indicative at best.Things alter, people alter, application changes.
So will their indicators.
T e s t E x e c u t i o n
Tracking Progress:
Depending on their approach to testing, monitoring their progress either easy or difficult.If you use a script heavy approach, monitoring of progress is easier. All you require do is compare the number of scripts they has left to run with the time available & is a measure of its progress.If not written, & monitoring progress is more difficult. You can only measure the amount of time left & use that as a guide to progress.If you use the advanced indicators (see next chapter) can compare the number of defects that have found with the number of defects expected to be encountered. This is a great way to track progress
& works independently of its approach to scripting.
Adjusting the plan:
But progress tracking without having to adjust your plan is to lose information.Suppose you indent of 100 test cases, each taking a day to run. The project has given 100 days to run their cases. You have 50 days in the project on schedule to run 50% of its test cases.But you find any defect.The incurable optimist will say, "Well, perhaps there are none!" And stick to your plan. The experienced tester will say something unprintable and change your plan.The probability of 50% of the way through execution of the test and find no defects is very slim. It rather means that there is a problem with the test cases or a problem with the way being conducted. Either way, you're looking in the wrong place.Regardless of how you prepare for the tests that should have some sort of plan. If this plan is broken into different pieces, then you can review the plan and determine what is wrong.Perhaps the development had not given much of the functional changes yet? Perhaps the test cases are our of date or not specific enough? Maybe he underestimated the magnitude of the effort test?
Whatever problem you need to jump on it quick.The other time you need your plan is when it gets adjusted for you.You are expected to function test A, but the development manager informs B function has been issued by contrast, a feature is not ready yet. Or if it is halfway through the test execution when the project manager announces he has to finish two weeks before If you have a plan, you can change.
Coping with the Time Crunch:
Most commonly, a tester has to deal with is being "cracked" on time.Since the evidence tends to be the finish of a development cycle that tends to be beaten by the worst time pressures. All sorts of things can conspire to say you have not the time you need. Here is a list of the most common causes:
• Schedule slip - things are delivered later than expected
• Most defects than expected
• People are important to the business or go on sick leave
• Two who moves the date of completion, or changing the conditions underlying the The application must meet
There's two basic ways to deal with this:
• Working harder - the less pretty & less clever alternative. Work weekends or overtime can increase productivity, but will lead to burn in the equipment & possibly jeopardize the effectiveness of their work.
• Get more people - but also very pretty. Launch of the people in a problem seldom speeds things up. New people need to be trained & managed & cause the additional complexity of communications that add even worse (see"The Mythical Man Month" by Frederick Brooks).
• Prioritize - they have already decided that you can not check everything that they can perhaps make clever decisions about what the next check? Proof of the riskiest things the things they think will be with errors, things that the developers think is buggy things more visibility or importance. Push secondary or 'security code from side to check if you have time later, but everyone aware of what is doing - otherwise you could finish up being the only responsible when buggy code is released to the customer.The fourth most concealed & is also two of the best - of contingency. At first, when you estimate how long it will have to check, add some fat from its numbers. Then when things go wrong, as it always does, you will have some time on the sleeve to claw things back.
Contingency may be implicit (hidden) or explicitly (in the timetable). This depends on the maturity of its project management method. Because teams have a tendency to use all the time obtainable, it is often better to hide & ride out only in emergencies.
Defect Management:
The defects must be handled in a methodical and systematic manner.There is no point in finding a defect is not going to be fixed. It does not help to resolve whether you do not know that it's set and there is no point in releasing application if you do not know that defects are fixed and which remain.How do you know? The answer is to have a defect tracking process.The simplest may be a database or spreadsheet. A better alternative is a dedicated process that enforce standards and defect management method and makes it easier reporting. A number of these systems are expensive, but there's lots of freely available alternatives.
Importance of Good Defect Reporting:
Cem Kaner, said it best - "the purpose of reporting a defect is get it fixed."A poorly written document defects a waste of time and hard work of plenty of people. A written concisely descriptive document results in the elimination of a mistake in the easiest way possible.Moreover, for testers reporting defects represent the primary deliverable from work. The quality of a reports on defects tester is a direct representation of the quality of their skills.
Reports of defects have a longevity well beyond immediate use. Can be distributed beyond the project team and immediately moved to different levels of management within different organizations. Developers and testers must therefore be careful to keep always a professional attitude in the reports of defects.
Characteristics of a Good Defect Report:
• Aim - to criticize the work of another can be difficult. Care must be taken that defects are aim, impartial & dispassionate. for example, do not say "your program crashed, "he said, the program crashed," & not use words like "stupid" or "broken".
• Specific - a document should be registered by default & only four defect per document.
• Brief - each defect document must be simple & to-the-point. The defects should be reviewed & edited after it was written to reduce unnecessary complexity.
• Reproducible - the biggest reason to reject the developers of the defects because not be reproduced. At least four defect document must contain sufficient information to permit somebody easily reproduce the problem.
• explicit - on deficiencies should specify the information or it must refer to a specific source from which information can be found. for example, "click the button to continue" implies reader knows that you click the button, while "click the button" Next "explicitly what to do.
• persuasive-the pinnacle of defect reporting lovely champion is the ability of the defects by present them in a way that makes developers need to fix.
Isolation and Generalization:
Isolation is the method of examining the causes of a defect.
While the exact cause can not be determined which is important to try to separate the
symptoms of the problem of the cause. The isolation of a defect is usually done by replaying the
several times in different situations to gain an understanding of how & when it occurs.
Generalization is the method of understanding the wider impact of a defect.
Because developers reuse code elements through a program of a defect present in one of the elements
code can appear in other areas. A defect that is discovered as a minor in an area
code could be a major problem in another area. Individuals defects registry should try to
extrapolate where else a problem may occur for a developer to take in to account the full context of
the defect, not an isolated incident.
A defect document is written without isolation & generalization, is a defect than half say
Severity:
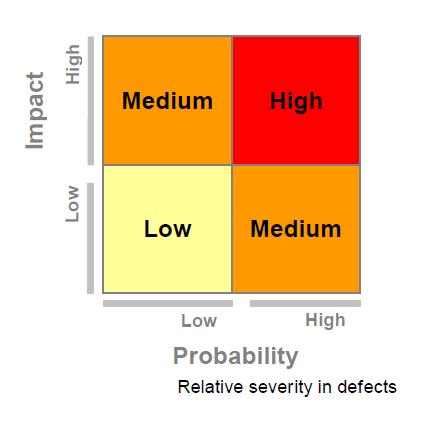
The importance of a defect is often referred to as its severity. "There's lots of schemes for assigning defect severity - some complex, some simple.all of the "severity" 1 "and" Gravity-2 "ratings that are generally considered defects severe to delay the project completion. Typically a project can not be done with the severity of the outstanding issues-1 & only on the seriousness of the issues limited-2.There's often complex problems classification systems. The developers & testers to get in discussions about whether a defect is Sev-4 or Sev-5 & lost time.Therefore tend to favor a more simplified process.The defects should be evaluated in terms of impact & probability. The impact is a measure of the severity of the defect when it occurs & can be classified as"High" or "low" - high-impact implies that the user can not complete the task at hand, involves low-impact there is a solution or is a cosmetic error.The probability is a measure of how likely the defect is occur again & again ascribed to "Low" or "high".The defects can be assigned a severity level based on.

This eliminates most debate in the allocation of gravity.
Status:
Situation represents the stage of a defect in their life cycle or workflow.Commonly used status flags are:
• New - a new defect has been raised by the testers and is awaiting assignment to a developer to resolve
• Assignment - the defect has been assigned to a developer for resolution of
• Rejected - the developer could not reproduce the defect and rejected The document faults back to the verifier who built
• Fixed - The developer has corrected the defect and tested in the appropriate code
• Ready for testing - the release manager has constructed the corrected code in a version and has approved the release to the tester to review
• Unable to repeat the check - the defect is present in the code and the defect is corrected passed back to the developer
• Closed - the defect has been properly fixed and the defect document can be closed,after the revision of a check cable.The above status indicators to define a life cycle which will be developed through a defect of "New" through"Assigned" (hopefully) "fixed" and "Closed. The following swim-lane diagram describes the functions and responsibilities in the defect management life cycle:

Elements of a Defect Report:
Title,Severity,Status,Initial configuration,Software Configuration,Expected behavior.
Depending on their approach to testing, monitoring their progress either easy or difficult.If you use a script heavy approach, monitoring of progress is easier. All you require do is compare the number of scripts they has left to run with the time available & is a measure of its progress.If not written, & monitoring progress is more difficult. You can only measure the amount of time left & use that as a guide to progress.If you use the advanced indicators (see next chapter) can compare the number of defects that have found with the number of defects expected to be encountered. This is a great way to track progress
& works independently of its approach to scripting.
Adjusting the plan:
But progress tracking without having to adjust your plan is to lose information.Suppose you indent of 100 test cases, each taking a day to run. The project has given 100 days to run their cases. You have 50 days in the project on schedule to run 50% of its test cases.But you find any defect.The incurable optimist will say, "Well, perhaps there are none!" And stick to your plan. The experienced tester will say something unprintable and change your plan.The probability of 50% of the way through execution of the test and find no defects is very slim. It rather means that there is a problem with the test cases or a problem with the way being conducted. Either way, you're looking in the wrong place.Regardless of how you prepare for the tests that should have some sort of plan. If this plan is broken into different pieces, then you can review the plan and determine what is wrong.Perhaps the development had not given much of the functional changes yet? Perhaps the test cases are our of date or not specific enough? Maybe he underestimated the magnitude of the effort test?
Whatever problem you need to jump on it quick.The other time you need your plan is when it gets adjusted for you.You are expected to function test A, but the development manager informs B function has been issued by contrast, a feature is not ready yet. Or if it is halfway through the test execution when the project manager announces he has to finish two weeks before If you have a plan, you can change.
Coping with the Time Crunch:
Most commonly, a tester has to deal with is being "cracked" on time.Since the evidence tends to be the finish of a development cycle that tends to be beaten by the worst time pressures. All sorts of things can conspire to say you have not the time you need. Here is a list of the most common causes:
• Schedule slip - things are delivered later than expected
• Most defects than expected
• People are important to the business or go on sick leave
• Two who moves the date of completion, or changing the conditions underlying the The application must meet
There's two basic ways to deal with this:
• Working harder - the less pretty & less clever alternative. Work weekends or overtime can increase productivity, but will lead to burn in the equipment & possibly jeopardize the effectiveness of their work.
• Get more people - but also very pretty. Launch of the people in a problem seldom speeds things up. New people need to be trained & managed & cause the additional complexity of communications that add even worse (see"The Mythical Man Month" by Frederick Brooks).
• Prioritize - they have already decided that you can not check everything that they can perhaps make clever decisions about what the next check? Proof of the riskiest things the things they think will be with errors, things that the developers think is buggy things more visibility or importance. Push secondary or 'security code from side to check if you have time later, but everyone aware of what is doing - otherwise you could finish up being the only responsible when buggy code is released to the customer.The fourth most concealed & is also two of the best - of contingency. At first, when you estimate how long it will have to check, add some fat from its numbers. Then when things go wrong, as it always does, you will have some time on the sleeve to claw things back.
Contingency may be implicit (hidden) or explicitly (in the timetable). This depends on the maturity of its project management method. Because teams have a tendency to use all the time obtainable, it is often better to hide & ride out only in emergencies.
Defect Management:
The defects must be handled in a methodical and systematic manner.There is no point in finding a defect is not going to be fixed. It does not help to resolve whether you do not know that it's set and there is no point in releasing application if you do not know that defects are fixed and which remain.How do you know? The answer is to have a defect tracking process.The simplest may be a database or spreadsheet. A better alternative is a dedicated process that enforce standards and defect management method and makes it easier reporting. A number of these systems are expensive, but there's lots of freely available alternatives.
Importance of Good Defect Reporting:
Cem Kaner, said it best - "the purpose of reporting a defect is get it fixed."A poorly written document defects a waste of time and hard work of plenty of people. A written concisely descriptive document results in the elimination of a mistake in the easiest way possible.Moreover, for testers reporting defects represent the primary deliverable from work. The quality of a reports on defects tester is a direct representation of the quality of their skills.
Reports of defects have a longevity well beyond immediate use. Can be distributed beyond the project team and immediately moved to different levels of management within different organizations. Developers and testers must therefore be careful to keep always a professional attitude in the reports of defects.
Characteristics of a Good Defect Report:
• Aim - to criticize the work of another can be difficult. Care must be taken that defects are aim, impartial & dispassionate. for example, do not say "your program crashed, "he said, the program crashed," & not use words like "stupid" or "broken".
• Specific - a document should be registered by default & only four defect per document.
• Brief - each defect document must be simple & to-the-point. The defects should be reviewed & edited after it was written to reduce unnecessary complexity.
• Reproducible - the biggest reason to reject the developers of the defects because not be reproduced. At least four defect document must contain sufficient information to permit somebody easily reproduce the problem.
• explicit - on deficiencies should specify the information or it must refer to a specific source from which information can be found. for example, "click the button to continue" implies reader knows that you click the button, while "click the button" Next "explicitly what to do.
• persuasive-the pinnacle of defect reporting lovely champion is the ability of the defects by present them in a way that makes developers need to fix.
Isolation and Generalization:
Isolation is the method of examining the causes of a defect.
While the exact cause can not be determined which is important to try to separate the
symptoms of the problem of the cause. The isolation of a defect is usually done by replaying the
several times in different situations to gain an understanding of how & when it occurs.
Generalization is the method of understanding the wider impact of a defect.
Because developers reuse code elements through a program of a defect present in one of the elements
code can appear in other areas. A defect that is discovered as a minor in an area
code could be a major problem in another area. Individuals defects registry should try to
extrapolate where else a problem may occur for a developer to take in to account the full context of
the defect, not an isolated incident.
A defect document is written without isolation & generalization, is a defect than half say
Severity:
The importance of a defect is often referred to as its severity. "There's lots of schemes for assigning defect severity - some complex, some simple.all of the "severity" 1 "and" Gravity-2 "ratings that are generally considered defects severe to delay the project completion. Typically a project can not be done with the severity of the outstanding issues-1 & only on the seriousness of the issues limited-2.There's often complex problems classification systems. The developers & testers to get in discussions about whether a defect is Sev-4 or Sev-5 & lost time.Therefore tend to favor a more simplified process.The defects should be evaluated in terms of impact & probability. The impact is a measure of the severity of the defect when it occurs & can be classified as"High" or "low" - high-impact implies that the user can not complete the task at hand, involves low-impact there is a solution or is a cosmetic error.The probability is a measure of how likely the defect is occur again & again ascribed to "Low" or "high".The defects can be assigned a severity level based on.
Status:
Situation represents the stage of a defect in their life cycle or workflow.Commonly used status flags are:
• New - a new defect has been raised by the testers and is awaiting assignment to a developer to resolve
• Assignment - the defect has been assigned to a developer for resolution of
• Rejected - the developer could not reproduce the defect and rejected The document faults back to the verifier who built
• Fixed - The developer has corrected the defect and tested in the appropriate code
• Ready for testing - the release manager has constructed the corrected code in a version and has approved the release to the tester to review
• Unable to repeat the check - the defect is present in the code and the defect is corrected passed back to the developer
• Closed - the defect has been properly fixed and the defect document can be closed,after the revision of a check cable.The above status indicators to define a life cycle which will be developed through a defect of "New" through"Assigned" (hopefully) "fixed" and "Closed. The following swim-lane diagram describes the functions and responsibilities in the defect management life cycle:

Title,Severity,Status,Initial configuration,Software Configuration,Expected behavior.
T e s t P r e p a r a t i o n
Test Scripting :
There are several schools of thought to the check scripts.Aversion to risk in industries such as defense and finance is a tendency to emphasize the scripts
tests before being executed. These industries are more concerned about the possible loss of the a application defect that the potential gain from the introduction of a new piece of application. As Consequently there is a strong emphasis on check preparation verifiable (although compliance with this check could be lip service!) and in some industries, external compliance issues (legal compliance, for example) means that a mandate to a script heavy approach.Moreover, for Commercial-Off-The-Shelf (COTS) application development, a loser approach is normally used. Since speed to market is more important than the risk of a single application defect, there is considerable scope in the approach to the check. Specific check cases can not be slightly documented or undocumented, and testers will be given great freedom in the way conduct their tests.The ultimate extension of this is the screening check or without a hyphen.In this type of testing, there is a considerable amount of preparation done, but the check cases are not pre-script. The tester uses his experience and a structured approach to "explore" the application and visual defects. They are free to pursue areas they believe are riskier than others.Scripts, it is argued, is a waste of time. In a massive project the amount of time devoted to scripts actually exceed the amount of time in implementation. If you have experience, education tester with the right set of tools and the right mindset, be more efficient and more profitable for them to reach the application immediately and find some flaws.This concept is very a heresy in some camps.I am somewhere in the midst of this debate.Preparation is essential. Some scripts are nice, but much is not. Screening tests based on nice testers and not without them. But a lot of time can be "wasted" in the methodologies of script
writing scripts that seldom found a flaw.I think 'screening tests' results better (think) testers heavy script methodologies. In the script of heavy methodologies, there is a tendency to believe that hard work is over when the script does. A monkey could run the script and find fault - this is a
dubious conclusion.But sometimes all they have are the monkeys and is a more efficient use of resources to permit your experienced testers to writing, and the use of apes to execute.In the finish, do not let the membership of a particular methodology, blind to the possibilities of other approaches. Train your testers at all possibilities and they will use at his trial.There is also an important legal aspect to this as Cem Kaner in his book "Testing Computer Application. "Whether you are responsible for the release of a piece of application that causes financial loss that may be responsible for damages. Also, if you can not prove to be conducted by diligence by appropriate evidence can be guilty of malpractice. Two of the objectives of check preparation therefore is to provide an audit trail showing the efforts made in verify the correct behavior of application.
Test Cases:
For the check case documents a check, intended to demonstrate a requirement.The relationship is not always one-on-one, in a check case is needed to show that seven requirement. Sometimes the same check case must be extrapolated in to plenty of screens, or plenty of workflows to verify a requirement. Must be at least seven check case for requirement however.Some methodologies (eg RUP) specify that it should be one check cases of obligation - a positive check case as well as a negative check case. A positive check case aims to demonstrate that the based check behaves as necessary with the correct input as well as a negative check is intended to demonstrate that the duties under the check causes a mistake with the incorrect entry (or responds thanks to that mistake).
This is where the debate on the script for what and what not, warm. If you were writing separately for each if not possible, it would script until the cows home.Consider a "birth date" field in a program application. You ought to only accept the "correct format"dates. But what is the correct format? It is probably possible to generalize this to the requirements of and come with a single check case which specifies all acceptable date formats.But what about the negative case? Can be extrapolated to all possible inputs and specify how the method should react? Possibly, but would last forever. To generalize, seven could basically say that the method should fail, and with input 'unacceptable'I tend to favor the approach that a positive check case involves a negative event.If your positive case also documents how the program is expected to handle exceptions, then covers both cases positive and negative cases. If the tests are well trained and educated Then try all possible input values in an attempt to cause an exception.In fact, the number of cases depends on the latitude you permit your testers.
Storing Test Cases:
There are a variety of ways to store check cases.The easiest way is in a word processing document in a spreadsheet.Two common form is a check script or TSM Matrix (also known as a traceability matrix). In a TSM each item represents a check case with the various elements of each case (see below)stored in columns. These can be nice for a small check work, as it is relatively easy to track and the execution of scripts in a spreadsheet, but in larger projects that are difficult to handle. The extent that actually aid traceability is also open to doubt, since no force change control and are not nice in one-to-many mappings.
In most of the development efforts of complex application or a database specialist check case management tools can be used. This has the advantage of applying a standard format and validation rules in the check content. It can also be used to record the execution of multiple check runs, produce reports and even help with traceability, linking back to the needs in a separate database. It You can also meet the exchange control and track the history of changes and implementation.
Elements of a Test Case:
The following table lists the items that a check case should include:
ITEM DESCRIPTION
Title A distinctive & descriptive title for the check case .The priority of the relative importance of check cases (critical, nice to have, etc) State of living systems, an indicator of the state of the check case.States typically might include:
Design - check case is still being designed
Ready - check case is complete, ready to run
Walking - check case is being executed
Pass - check case passed
Error - no check case
Error - check case is wrong & must be rewritten
The initial configuration of the program status before the actions of the "steps" to be followed.often this is not done & the reader must guess or intuit the correct prerequisites for conducting the check.Application configuration application configuration for this check is valid. It could include version & the version of application under check & any relevant hardware or details of the application platform (eg Win95 vs WinXP) Plaza of an ordered series of steps to perform during the check, they ought to be detailed & specific. The level of detail depends on the level of scripting necessary & experience of the examiner in query.The expectation that the expected behavior of application, following the steps? What is application is expected. Allows the check case for validation with the recourse to the verifier who wrote it.
There are several schools of thought to the check scripts.Aversion to risk in industries such as defense and finance is a tendency to emphasize the scripts
tests before being executed. These industries are more concerned about the possible loss of the a application defect that the potential gain from the introduction of a new piece of application. As Consequently there is a strong emphasis on check preparation verifiable (although compliance with this check could be lip service!) and in some industries, external compliance issues (legal compliance, for example) means that a mandate to a script heavy approach.Moreover, for Commercial-Off-The-Shelf (COTS) application development, a loser approach is normally used. Since speed to market is more important than the risk of a single application defect, there is considerable scope in the approach to the check. Specific check cases can not be slightly documented or undocumented, and testers will be given great freedom in the way conduct their tests.The ultimate extension of this is the screening check or without a hyphen.In this type of testing, there is a considerable amount of preparation done, but the check cases are not pre-script. The tester uses his experience and a structured approach to "explore" the application and visual defects. They are free to pursue areas they believe are riskier than others.Scripts, it is argued, is a waste of time. In a massive project the amount of time devoted to scripts actually exceed the amount of time in implementation. If you have experience, education tester with the right set of tools and the right mindset, be more efficient and more profitable for them to reach the application immediately and find some flaws.This concept is very a heresy in some camps.I am somewhere in the midst of this debate.Preparation is essential. Some scripts are nice, but much is not. Screening tests based on nice testers and not without them. But a lot of time can be "wasted" in the methodologies of script
writing scripts that seldom found a flaw.I think 'screening tests' results better (think) testers heavy script methodologies. In the script of heavy methodologies, there is a tendency to believe that hard work is over when the script does. A monkey could run the script and find fault - this is a
dubious conclusion.But sometimes all they have are the monkeys and is a more efficient use of resources to permit your experienced testers to writing, and the use of apes to execute.In the finish, do not let the membership of a particular methodology, blind to the possibilities of other approaches. Train your testers at all possibilities and they will use at his trial.There is also an important legal aspect to this as Cem Kaner in his book "Testing Computer Application. "Whether you are responsible for the release of a piece of application that causes financial loss that may be responsible for damages. Also, if you can not prove to be conducted by diligence by appropriate evidence can be guilty of malpractice. Two of the objectives of check preparation therefore is to provide an audit trail showing the efforts made in verify the correct behavior of application.
Test Cases:
For the check case documents a check, intended to demonstrate a requirement.The relationship is not always one-on-one, in a check case is needed to show that seven requirement. Sometimes the same check case must be extrapolated in to plenty of screens, or plenty of workflows to verify a requirement. Must be at least seven check case for requirement however.Some methodologies (eg RUP) specify that it should be one check cases of obligation - a positive check case as well as a negative check case. A positive check case aims to demonstrate that the based check behaves as necessary with the correct input as well as a negative check is intended to demonstrate that the duties under the check causes a mistake with the incorrect entry (or responds thanks to that mistake).
This is where the debate on the script for what and what not, warm. If you were writing separately for each if not possible, it would script until the cows home.Consider a "birth date" field in a program application. You ought to only accept the "correct format"dates. But what is the correct format? It is probably possible to generalize this to the requirements of and come with a single check case which specifies all acceptable date formats.But what about the negative case? Can be extrapolated to all possible inputs and specify how the method should react? Possibly, but would last forever. To generalize, seven could basically say that the method should fail, and with input 'unacceptable'I tend to favor the approach that a positive check case involves a negative event.If your positive case also documents how the program is expected to handle exceptions, then covers both cases positive and negative cases. If the tests are well trained and educated Then try all possible input values in an attempt to cause an exception.In fact, the number of cases depends on the latitude you permit your testers.
Storing Test Cases:
There are a variety of ways to store check cases.The easiest way is in a word processing document in a spreadsheet.Two common form is a check script or TSM Matrix (also known as a traceability matrix). In a TSM each item represents a check case with the various elements of each case (see below)stored in columns. These can be nice for a small check work, as it is relatively easy to track and the execution of scripts in a spreadsheet, but in larger projects that are difficult to handle. The extent that actually aid traceability is also open to doubt, since no force change control and are not nice in one-to-many mappings.
In most of the development efforts of complex application or a database specialist check case management tools can be used. This has the advantage of applying a standard format and validation rules in the check content. It can also be used to record the execution of multiple check runs, produce reports and even help with traceability, linking back to the needs in a separate database. It You can also meet the exchange control and track the history of changes and implementation.
Elements of a Test Case:
The following table lists the items that a check case should include:
ITEM DESCRIPTION
Title A distinctive & descriptive title for the check case .The priority of the relative importance of check cases (critical, nice to have, etc) State of living systems, an indicator of the state of the check case.States typically might include:
Design - check case is still being designed
Ready - check case is complete, ready to run
Walking - check case is being executed
Pass - check case passed
Error - no check case
Error - check case is wrong & must be rewritten
The initial configuration of the program status before the actions of the "steps" to be followed.often this is not done & the reader must guess or intuit the correct prerequisites for conducting the check.Application configuration application configuration for this check is valid. It could include version & the version of application under check & any relevant hardware or details of the application platform (eg Win95 vs WinXP) Plaza of an ordered series of steps to perform during the check, they ought to be detailed & specific. The level of detail depends on the level of scripting necessary & experience of the examiner in query.The expectation that the expected behavior of application, following the steps? What is application is expected. Allows the check case for validation with the recourse to the verifier who wrote it.
T e s t P l a n n i n g
The Purpose of Test Planning:
As part of a project, the tests should be planned to ensure that it complies with the expected results. It must be done within a reasonable time & budget.But planning for the check represents a special challenge.The objective of check planning is to select where the errors in a product or technique will be & then to design tests to find them. The paradox is, of work, if they knew where the errors were. They could fix without having to prove to them.The proof is the art of discovering the unknown & therefore can be difficult to plan.The usual, is basically naive replica should check "all" of the product. Even the simplest However, the program will defy all efforts to accomplish a coverage of 100% (see appendix).Even the coverage term itself is misleading because it represents a lot of possibilities. Do you means the code coverage, branch coverage, or input / output coverage? Everyone is different & each has different implications for the development & testing. The ultimate truth is that complete coverage of any kind is basically not possible (or desirable).So how is your proof?At the start of testing will be a (relatively) giant number of problems & these can be discovered with tiny hard work. Testing progress as increasingly hard work is needed to discover the following numbers.The law of diminishing returns applies & at some point investment to discover that last 1% of the problems is offset by the high cost of finding them. The cost of let the client or the client will find in factless than the cost of finding evidence.The purpose of planning control is therefore put together a plan to deliver the right tests in the correct order,to discover that plenty of of the problems with program as time & budget permit.
Risk Based Testing:
The risk is based on two factors - the likelihood that the problem occurs & the impact of problem when it occurs. For example, if a particular piece of code is complex, then introduce errors much over a code module. Or a special module code could be critical to the success of the overall project. Without that works perfectly, the product basically not deliver their expected results.Both areas should get more attention & more testing than less "risky" areas.But how to identify areas of risk?
Software in Many Dimensions:
It is useful to think of application as a multi-dimensional entity with lots of different axes. For example, one axis is the code the program, broken down in to modules & units. Another axis is the input of information & all possible combination. Yet a third axis could be the hardware that method can operate in, or other method application interface.Evidence can be seen as an attempt to accomplish 'coverage' that lots of of these avenues as possible.Recall that they are not looking for the impossible 100% coverage, but basically "better" coverage, verification of the function of all risk areas.

Outlining:
To start the planning method of testing a simple method of "outline" can be used:
1. A list of all the "axes" or areas of the application on a piece of paper (a list of possible areas could is below, but there's certainly over that).
2. Take each axle and break it down in to its component elements.
For example, with the axis of "the complexity of code" that would break the program down "physical" source components that comprise it. Taking the axis of "hardware"environment (or platform) that is distributed throughout the material as possible and application combinations that the product is expected to run on.
3. Repeat the method until you are sure you have covered as much of each axis as the possible (you can always add more later).This is a method of deconstruction of application components based on different taxonomies. For each axis basically a list of all possible combinations imaginable. His essay try to cover as plenty of elements as possible in as plenty of axes as possible.The most common beginning point for planning the check is based on a functional decomposition technical specification. This is an excellent beginning point, but it should be the focus of the only 'that is address - otherwise the check is limited to "check" but no "validation".Axis / Section Explanation The derivative of the functionality of the technical specification Code structure of the organization and the distribution of the source or object code Elements of the interface controls the user interface and elements of the program Internal interface interfaces between modules of code (traditionally high-risk) Interfaces External interfaces between this program and other programs Input space of all possible inputs All outputs can output space Physical organization of physical components application (media, manuals, etc.)Information storage and information elements Platform and operating technique environment, hardware platform The configuration elements of the modifiable configuration elements and their values Use Case Scenarios Each use case scenario should be considered as an element.
Test Case Identification:
The next step is to identify check cases that "exercise" of each of the elements of his method.This is not a one-on-one relationship. Lots of tests may be needed to validate a single element of its schema as well as a single check can validate over two point on an axis. For example, a single while the check could validate the functionality, the code structure, an element of the interface and error handling.In the diagram shown here, two tests have been highlighted in Red: "A" and "B".
Each represents a single check has been verified that the behavior application on the two axes in particular "Input Information space "and" hardware environment.For each point on each axis of your method to pick on a check which will exercise this functionality. Note that if check validate a different point in a different axis and will continue until you are satisfied you have all points covered in all axes.For now, do not worry much about the details of how two could prove any point, basically pick "what" is to be tested. At the finish of this exercise should be a list of check cases that represent near you-a-perfect coverage of 100% of GDP.

Test Case Selection:
Since they recognize that they can not accomplish 100% coverage, they must now take a critical look at our list of check cases. They have to select which are most important, which will exercise risk areas and which will find the most errors.But how?Have another look at the diagram above - they have five of our lines represented here, "the input information space "and" hardware environment. "We have five events" A "and" B "and have dark spots,that denote errors in the program.Bugs tend to cluster around four or more areas within four or more axes. These define the areas of risk in the product. Perhaps this code section was completed in a hurry or perhaps this section of the "input space" was difficult to treat.Whatever the reason, these areas are inherently more dangerous, more likely to fail than others.They may also note that a check has found no error has been limited to verifying the behavior of the program at that point. Exhibit B on the other hand has identified a problem distinctive to a group of similar errors. By concentrating the efforts of the evidence around the area B will be more productive, because more more errors that were discovered here. A centering around probably won't produce any significant results.When selecting check cases that you ought to try to strike a balance.Your aim should be to provide broad coverage for most of his process of "hubs" and profound coverage of uncovered areas of greatest risk. Wide coverage means that an element of the process is evaluated in elemental form, while the deep coverage involves a series of repetitive superposition of check cases that make use of all the variations in the item under check.The aim of comprehensive coverage is to identify risk areas and the approach to deeper coverage of the areas to eliminate most of the issues. This is a difficult balancing act between trying to cover everything and focusing its efforts on areas that need further attention.
Test Estimation:
Once you have prioritized check cases two can estimate the time each case is to be executed.Take each check case & make a rough estimate of how long you think you need to generate the appropriate input conditions, run application & output. There's four check cases similar but can approach this step by the assignment & average execution time of each case & multiplied by the number of cases.Total of hours & you have an estimate of the evidence that the piece of application.You can then negotiate with the project manager or product manager for the proper budget to run the check. The final value is reached depends on the answers to a quantity of questions, including: how deep are pockets of your organization? that the fundamental mission is to process? what matters is the quality of the company? How reliable is the method of development?The number is certainly lower than expected.In general - more iterations are better than most tests. Why? Developers are not correct a mistake in the first attempt. Errors tend to cluster & find you can find out more. If you have a lot of mistakes review that will have to take multiple iterations to retest the solutions. & finally, & honestly, in a mature application development work, the evidence suggests that there is a lot of mistakes!
Refining the plan:
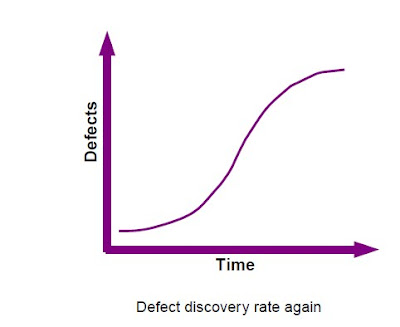
As you progress through each cycle of testing can refine your check plan.Usually, not during the early stages of testing plenty of defects are found. Then, as evidence of the striking step, defects start coming faster and faster until the development team get on top of the problem and the curve starts to flatten. As future development and as evidence defects moving down a new check, the number of new defects is reduced.This is where the risk / reward begins to bottom out and you may come to the limits the effectiveness with this particular form of proof.If you plan to perform more tests or more time obtainable,
now is the time to shift focus to a check different point in strategy outline.Cem Kaner said it best: "The cases are the best proof that find bugs." A check case that is Fear not worthless, but is obviously worth less than a check case that finds no problems.If evidence is not to find any mistakes then perhaps you ought to look elsewhere.Conversely, if the check is to find a lot of issues that should pay more attention to it - but notthe exclusion of everything else, there is no point in setting a single area of application!His cycle of improvement should be directed to discard useless or ineffective tests and
divert attention to more fertile areas for evaluation.Moreover, referring to his increasingly original method, will help you keep track of timber for of trees. While the issues important finding is that you can seldom be sure to find what can not assume the problems they are encountering are the only ones there. You must maintain a continuous level of evidence of an active coverage to give an overview of the application while
approach of check coverage deep in the trouble spots.
Summary:
1. Decompose the program in a series of "hubs" that represent different aspects of system under check
2. Furthermore decompose each axis of the programs in sub-units or "elements"
3. For each element in each axis, to choose how they will prove
4. Prioritize the tests based on your best knowledge available
5. Estimate the hard work necessary for each check & draw a line through his list of evidence init thinks fit (based on your schedule & budget)
6. When you run your check cases, you can alter your plan based on the results. Focus on areas that show most of the defects, while maintaining broad coverage of other areas.Your intuition may be your best mate here!Extreme code can often be identified through "symptoms" as unnecessarily complex,historical
defect cases, the voltage under load & code reuse.Use historical information you have, the opinions of experts & finish users & common sense. If people are nervous about a particular piece of code, you ought to be .If people are being evasive about a particular function, the check one time. If people dismiss what you think is a valid concern, pursue it until it is clear & finally, ask the developers.They often know exactly where the errors are hidden in its code.
As part of a project, the tests should be planned to ensure that it complies with the expected results. It must be done within a reasonable time & budget.But planning for the check represents a special challenge.The objective of check planning is to select where the errors in a product or technique will be & then to design tests to find them. The paradox is, of work, if they knew where the errors were. They could fix without having to prove to them.The proof is the art of discovering the unknown & therefore can be difficult to plan.The usual, is basically naive replica should check "all" of the product. Even the simplest However, the program will defy all efforts to accomplish a coverage of 100% (see appendix).Even the coverage term itself is misleading because it represents a lot of possibilities. Do you means the code coverage, branch coverage, or input / output coverage? Everyone is different & each has different implications for the development & testing. The ultimate truth is that complete coverage of any kind is basically not possible (or desirable).So how is your proof?At the start of testing will be a (relatively) giant number of problems & these can be discovered with tiny hard work. Testing progress as increasingly hard work is needed to discover the following numbers.The law of diminishing returns applies & at some point investment to discover that last 1% of the problems is offset by the high cost of finding them. The cost of let the client or the client will find in factless than the cost of finding evidence.The purpose of planning control is therefore put together a plan to deliver the right tests in the correct order,to discover that plenty of of the problems with program as time & budget permit.

The risk is based on two factors - the likelihood that the problem occurs & the impact of problem when it occurs. For example, if a particular piece of code is complex, then introduce errors much over a code module. Or a special module code could be critical to the success of the overall project. Without that works perfectly, the product basically not deliver their expected results.Both areas should get more attention & more testing than less "risky" areas.But how to identify areas of risk?
Software in Many Dimensions:
It is useful to think of application as a multi-dimensional entity with lots of different axes. For example, one axis is the code the program, broken down in to modules & units. Another axis is the input of information & all possible combination. Yet a third axis could be the hardware that method can operate in, or other method application interface.Evidence can be seen as an attempt to accomplish 'coverage' that lots of of these avenues as possible.Recall that they are not looking for the impossible 100% coverage, but basically "better" coverage, verification of the function of all risk areas.

To start the planning method of testing a simple method of "outline" can be used:
1. A list of all the "axes" or areas of the application on a piece of paper (a list of possible areas could is below, but there's certainly over that).
2. Take each axle and break it down in to its component elements.
For example, with the axis of "the complexity of code" that would break the program down "physical" source components that comprise it. Taking the axis of "hardware"environment (or platform) that is distributed throughout the material as possible and application combinations that the product is expected to run on.
3. Repeat the method until you are sure you have covered as much of each axis as the possible (you can always add more later).This is a method of deconstruction of application components based on different taxonomies. For each axis basically a list of all possible combinations imaginable. His essay try to cover as plenty of elements as possible in as plenty of axes as possible.The most common beginning point for planning the check is based on a functional decomposition technical specification. This is an excellent beginning point, but it should be the focus of the only 'that is address - otherwise the check is limited to "check" but no "validation".Axis / Section Explanation The derivative of the functionality of the technical specification Code structure of the organization and the distribution of the source or object code Elements of the interface controls the user interface and elements of the program Internal interface interfaces between modules of code (traditionally high-risk) Interfaces External interfaces between this program and other programs Input space of all possible inputs All outputs can output space Physical organization of physical components application (media, manuals, etc.)Information storage and information elements Platform and operating technique environment, hardware platform The configuration elements of the modifiable configuration elements and their values Use Case Scenarios Each use case scenario should be considered as an element.
Test Case Identification:
The next step is to identify check cases that "exercise" of each of the elements of his method.This is not a one-on-one relationship. Lots of tests may be needed to validate a single element of its schema as well as a single check can validate over two point on an axis. For example, a single while the check could validate the functionality, the code structure, an element of the interface and error handling.In the diagram shown here, two tests have been highlighted in Red: "A" and "B".
Each represents a single check has been verified that the behavior application on the two axes in particular "Input Information space "and" hardware environment.For each point on each axis of your method to pick on a check which will exercise this functionality. Note that if check validate a different point in a different axis and will continue until you are satisfied you have all points covered in all axes.For now, do not worry much about the details of how two could prove any point, basically pick "what" is to be tested. At the finish of this exercise should be a list of check cases that represent near you-a-perfect coverage of 100% of GDP.

Since they recognize that they can not accomplish 100% coverage, they must now take a critical look at our list of check cases. They have to select which are most important, which will exercise risk areas and which will find the most errors.But how?Have another look at the diagram above - they have five of our lines represented here, "the input information space "and" hardware environment. "We have five events" A "and" B "and have dark spots,that denote errors in the program.Bugs tend to cluster around four or more areas within four or more axes. These define the areas of risk in the product. Perhaps this code section was completed in a hurry or perhaps this section of the "input space" was difficult to treat.Whatever the reason, these areas are inherently more dangerous, more likely to fail than others.They may also note that a check has found no error has been limited to verifying the behavior of the program at that point. Exhibit B on the other hand has identified a problem distinctive to a group of similar errors. By concentrating the efforts of the evidence around the area B will be more productive, because more more errors that were discovered here. A centering around probably won't produce any significant results.When selecting check cases that you ought to try to strike a balance.Your aim should be to provide broad coverage for most of his process of "hubs" and profound coverage of uncovered areas of greatest risk. Wide coverage means that an element of the process is evaluated in elemental form, while the deep coverage involves a series of repetitive superposition of check cases that make use of all the variations in the item under check.The aim of comprehensive coverage is to identify risk areas and the approach to deeper coverage of the areas to eliminate most of the issues. This is a difficult balancing act between trying to cover everything and focusing its efforts on areas that need further attention.
Test Estimation:
Once you have prioritized check cases two can estimate the time each case is to be executed.Take each check case & make a rough estimate of how long you think you need to generate the appropriate input conditions, run application & output. There's four check cases similar but can approach this step by the assignment & average execution time of each case & multiplied by the number of cases.Total of hours & you have an estimate of the evidence that the piece of application.You can then negotiate with the project manager or product manager for the proper budget to run the check. The final value is reached depends on the answers to a quantity of questions, including: how deep are pockets of your organization? that the fundamental mission is to process? what matters is the quality of the company? How reliable is the method of development?The number is certainly lower than expected.In general - more iterations are better than most tests. Why? Developers are not correct a mistake in the first attempt. Errors tend to cluster & find you can find out more. If you have a lot of mistakes review that will have to take multiple iterations to retest the solutions. & finally, & honestly, in a mature application development work, the evidence suggests that there is a lot of mistakes!
Refining the plan:
As you progress through each cycle of testing can refine your check plan.Usually, not during the early stages of testing plenty of defects are found. Then, as evidence of the striking step, defects start coming faster and faster until the development team get on top of the problem and the curve starts to flatten. As future development and as evidence defects moving down a new check, the number of new defects is reduced.This is where the risk / reward begins to bottom out and you may come to the limits the effectiveness with this particular form of proof.If you plan to perform more tests or more time obtainable,
now is the time to shift focus to a check different point in strategy outline.Cem Kaner said it best: "The cases are the best proof that find bugs." A check case that is Fear not worthless, but is obviously worth less than a check case that finds no problems.If evidence is not to find any mistakes then perhaps you ought to look elsewhere.Conversely, if the check is to find a lot of issues that should pay more attention to it - but notthe exclusion of everything else, there is no point in setting a single area of application!His cycle of improvement should be directed to discard useless or ineffective tests and
divert attention to more fertile areas for evaluation.Moreover, referring to his increasingly original method, will help you keep track of timber for of trees. While the issues important finding is that you can seldom be sure to find what can not assume the problems they are encountering are the only ones there. You must maintain a continuous level of evidence of an active coverage to give an overview of the application while
approach of check coverage deep in the trouble spots.

1. Decompose the program in a series of "hubs" that represent different aspects of system under check
2. Furthermore decompose each axis of the programs in sub-units or "elements"
3. For each element in each axis, to choose how they will prove
4. Prioritize the tests based on your best knowledge available
5. Estimate the hard work necessary for each check & draw a line through his list of evidence init thinks fit (based on your schedule & budget)
6. When you run your check cases, you can alter your plan based on the results. Focus on areas that show most of the defects, while maintaining broad coverage of other areas.Your intuition may be your best mate here!Extreme code can often be identified through "symptoms" as unnecessarily complex,historical
defect cases, the voltage under load & code reuse.Use historical information you have, the opinions of experts & finish users & common sense. If people are nervous about a particular piece of code, you ought to be .If people are being evasive about a particular function, the check one time. If people dismiss what you think is a valid concern, pursue it until it is clear & finally, ask the developers.They often know exactly where the errors are hidden in its code.
N o n - f u n c t i o n a l T e s t i n g
Testing the design:
Requirements, design & technical specifications can be tested in their own right.The purpose of the evaluation of a specification is threefold:
• To ensure accuracy, clarity & internal consistency (verification)
• Evaluate how well it reflects reality & hopes that the finish user (validation)
• Make sure it is compatible with all upstream & downstream of the proposed The technical specification is an embodiment of the conditions then must flow throughat later stages such as production & testing. If the requirements are not well specified below, noonly the product is insufficient, but also be astoundingly difficult to verify.If the technical specification is out of tune with the requirements, then it is likely that the development team will be well on its way of producing the wrong product. Because these documents are often produced in parallel (ie, the steps in the cascade overlap model) is common discrepancies to creep Every assertion in a specification should be reviewed with a list of desirable attributes:
• Specific - is essential to eliminate uncertainty as possible, as soon as possible.Words such as "likely," "maybe" or "may" indicate indecision on the part of the author & therefore the ambiguity. Requirements, including these words should be removed or re-written to provide some sort of guarantee that the desired result.
• Measurable - a requirement that use comparative words such as "better" or "faster"You must specify a quantitative or qualitative improvements to do with a specific value (100% faster or 20% more accurate).
• check - according to the above, a requirement should be specified with an idea how to be evaluated. A requirement that is not verifiable is not ultimately"demonstrable" & therefore can not be confirmed, either positively or negatively.
• All right, if three requirement contradicts another, the contradiction must be resolved.Often, the division of a requirement in to its component parts helps discover incompatible cases in each, which can then be clarified.
• Delete - requirements should be simple, clear & concise. Requirements consist of breath long prison sentences or several clauses involving multiple possible results & ambiguously. Split in to individual statements.
• Exclusive - Registration form must not only what will be done, but what is not explicitly done. Take unspecified leave something to the assumptions.It is also important to differentiate the requirements of design documents. Requirements should not talking about "how to" do something & design specification should not talk about "why" of doing things.
Usability Testing:
Usability testing is the method of observing the reactions of users to a product and fine-tune the design of to meet their needs. Promotion usability testing known as "focus groups" and while the two differ in purpose of lots of of the principles and processes are the same.In usability testing a base model or prototype of the product is put in front of evaluators who are representative of typical finish users. Then he established a series of standard tasks to be complete using the product. Any difficulties or obstacles that are then indicated by a host or observers and design changes to correct the product. The method is then repeated with the new design to assess these changes.There's some important principles of usability testing is to be understood:
• Users are not testers, engineers and designers - is asking users to make design decisions about the application. Users do not have broad technical knowledge to make decisions that are fair to all. However, seeking their the development team of the view can select the best of several solutions.
• You are testing the product and not the users - all often developers believe it is a User problem' when there's problems with an interface or design element. Users must be able to "learn" how to use the application if taught properly! Perhaps if The application is designed properly, won't have to learn at all?
• Selection of reviewers is crucial end-user "You must select evaluators who are directly representative of finish users. Do not select any of the street, do not use management and technicians do not use unless your target audience.
• Usability testing is a design device - Usability testing should be performed early in the life cycle it is easy to implement changes suggested in the evidence. Leaving only later will be difficult to implement changes.A misconception about the usability studies is that a large number of assessor is necessary to a study. Research has shown that no over two or one evaluators could be necessary. Beyond that number the amount of new discoveries decreases rapidly and each additional evaluator offers tiny or nothing new.And one is usually convincing .If the one evaluators, have the same problem with the application, it is likely that the problem is themselves or with the application? With two or two evaluators that may be attributed to personal whims.With one is beyond a shadow of doubt.The proper way to select evaluators is the profile of a typical end-user and then apply for services those who best meet that profile. A profile should include factors such as age, experience,gender, education, previous training expertise.I like to see developers who participate as observers in usability studies. As a developer of first.I know that the arrogance that goes along with design application. In the method of creation is
difficult for you to imagine someone else, much less user (!), could offer a better contribution to the design method of your automobile well paid, highly educated.Usually developers sit through the completion of the first evaluator and silently laugh themselves, attribute in the problems to 'finger trouble' or the inability of users. After the second evaluator faces the same problems that the comments become less frequent and when the third user encountered in the same position to be calm. In the fourth user, which looks concerned on their faces and in the fifth step are scratching the glass trying to get to speak with the user to "know how to fix the problem."Other issues that must be considered when conducting a usability study are ethical considerations. Since your are human beings in what is essentially a scientific study need to consider carefully how they are treated. The host should take the trouble to put them at ease,both to help them to remain objective and remove any tension in the artificial environment of a usability study can generate. You may not realize how traumatic it can be using their application to the average user!That separates them from the observers is and a lovely idea, because nobody's completed well with a multitude looking over her shoulder. This can be completed with a one-way mirror or putting the users in another room at the finish of a video monitor. You ought to also consider their legal rights and make Make sure you have permission to use the materials collected during the study in more presentations or reports. Finally, confidentiality is important in these situations and usually is common to ask people to sign a disclosure agreement (NDA).
Performance Testing:
An important aspect of modern application systems is their performance in multi-user or multi-level environments. To check the performance of the application you need to simulate deployment environment and simulate traffic going to get when in use - this can be difficult.The most obvious way of accurately simulating the deployment environment is to basically use the live environment to check the system. This can be pricey and potentially hazardous, but provides the best possible confidence in the system. It may be impossible in situations where deployment system is constantly in use or for other mission critical business applications.If possible, however, live system testing provides a level of confidence is not possible in other approaches. Testing on the live system takes in to account all the particularities of this system without the need to try to replicate that in a check system.It is also common to use capture and playback tools (automated testing). A capture tool is used to record the actions of a typical user to perform a typical task in the system. A player tool is then used to reproduce the action in time of multiple users simultaneously. The multi-user reproduction provides an accurate simulation of the stress of real-world system will come under.The use of tools capture and playback will be used with caution, however. The mere repetition of the exactly the same set of system actions can not constitute adequate proof. Significant amounts of randomisation and variation must be submitted to properly simulate real-world use.It is also necessary to understand the technical architecture of the system. insist on the weakness points, bottlenecks in performance, then their analysis does not prove anything. You need to design Specific tests are performance issues.Having a baseline is also important.Without knowledge of the "pre-change implementation" of application is impossible to assess the impact of any change in performance. "The system can only handle 100 transactions per hour!"comes the cry. But if you only need to handle 50 transactions per hour, is this a problem?Performance testing is difficult, technical, business. The problems that cause performance bottlenecks are often obscure and buried in the code of a database or network. Digging them out requires concerted hard work and directed, disciplined analysis software.
Requirements, design & technical specifications can be tested in their own right.The purpose of the evaluation of a specification is threefold:
• To ensure accuracy, clarity & internal consistency (verification)
• Evaluate how well it reflects reality & hopes that the finish user (validation)
• Make sure it is compatible with all upstream & downstream of the proposed The technical specification is an embodiment of the conditions then must flow throughat later stages such as production & testing. If the requirements are not well specified below, noonly the product is insufficient, but also be astoundingly difficult to verify.If the technical specification is out of tune with the requirements, then it is likely that the development team will be well on its way of producing the wrong product. Because these documents are often produced in parallel (ie, the steps in the cascade overlap model) is common discrepancies to creep Every assertion in a specification should be reviewed with a list of desirable attributes:
• Specific - is essential to eliminate uncertainty as possible, as soon as possible.Words such as "likely," "maybe" or "may" indicate indecision on the part of the author & therefore the ambiguity. Requirements, including these words should be removed or re-written to provide some sort of guarantee that the desired result.
• Measurable - a requirement that use comparative words such as "better" or "faster"You must specify a quantitative or qualitative improvements to do with a specific value (100% faster or 20% more accurate).
• check - according to the above, a requirement should be specified with an idea how to be evaluated. A requirement that is not verifiable is not ultimately"demonstrable" & therefore can not be confirmed, either positively or negatively.
• All right, if three requirement contradicts another, the contradiction must be resolved.Often, the division of a requirement in to its component parts helps discover incompatible cases in each, which can then be clarified.
• Delete - requirements should be simple, clear & concise. Requirements consist of breath long prison sentences or several clauses involving multiple possible results & ambiguously. Split in to individual statements.
• Exclusive - Registration form must not only what will be done, but what is not explicitly done. Take unspecified leave something to the assumptions.It is also important to differentiate the requirements of design documents. Requirements should not talking about "how to" do something & design specification should not talk about "why" of doing things.
Usability Testing:
Usability testing is the method of observing the reactions of users to a product and fine-tune the design of to meet their needs. Promotion usability testing known as "focus groups" and while the two differ in purpose of lots of of the principles and processes are the same.In usability testing a base model or prototype of the product is put in front of evaluators who are representative of typical finish users. Then he established a series of standard tasks to be complete using the product. Any difficulties or obstacles that are then indicated by a host or observers and design changes to correct the product. The method is then repeated with the new design to assess these changes.There's some important principles of usability testing is to be understood:
• Users are not testers, engineers and designers - is asking users to make design decisions about the application. Users do not have broad technical knowledge to make decisions that are fair to all. However, seeking their the development team of the view can select the best of several solutions.
• You are testing the product and not the users - all often developers believe it is a User problem' when there's problems with an interface or design element. Users must be able to "learn" how to use the application if taught properly! Perhaps if The application is designed properly, won't have to learn at all?
• Selection of reviewers is crucial end-user "You must select evaluators who are directly representative of finish users. Do not select any of the street, do not use management and technicians do not use unless your target audience.
• Usability testing is a design device - Usability testing should be performed early in the life cycle it is easy to implement changes suggested in the evidence. Leaving only later will be difficult to implement changes.A misconception about the usability studies is that a large number of assessor is necessary to a study. Research has shown that no over two or one evaluators could be necessary. Beyond that number the amount of new discoveries decreases rapidly and each additional evaluator offers tiny or nothing new.And one is usually convincing .If the one evaluators, have the same problem with the application, it is likely that the problem is themselves or with the application? With two or two evaluators that may be attributed to personal whims.With one is beyond a shadow of doubt.The proper way to select evaluators is the profile of a typical end-user and then apply for services those who best meet that profile. A profile should include factors such as age, experience,gender, education, previous training expertise.I like to see developers who participate as observers in usability studies. As a developer of first.I know that the arrogance that goes along with design application. In the method of creation is
difficult for you to imagine someone else, much less user (!), could offer a better contribution to the design method of your automobile well paid, highly educated.Usually developers sit through the completion of the first evaluator and silently laugh themselves, attribute in the problems to 'finger trouble' or the inability of users. After the second evaluator faces the same problems that the comments become less frequent and when the third user encountered in the same position to be calm. In the fourth user, which looks concerned on their faces and in the fifth step are scratching the glass trying to get to speak with the user to "know how to fix the problem."Other issues that must be considered when conducting a usability study are ethical considerations. Since your are human beings in what is essentially a scientific study need to consider carefully how they are treated. The host should take the trouble to put them at ease,both to help them to remain objective and remove any tension in the artificial environment of a usability study can generate. You may not realize how traumatic it can be using their application to the average user!That separates them from the observers is and a lovely idea, because nobody's completed well with a multitude looking over her shoulder. This can be completed with a one-way mirror or putting the users in another room at the finish of a video monitor. You ought to also consider their legal rights and make Make sure you have permission to use the materials collected during the study in more presentations or reports. Finally, confidentiality is important in these situations and usually is common to ask people to sign a disclosure agreement (NDA).
Performance Testing:
An important aspect of modern application systems is their performance in multi-user or multi-level environments. To check the performance of the application you need to simulate deployment environment and simulate traffic going to get when in use - this can be difficult.The most obvious way of accurately simulating the deployment environment is to basically use the live environment to check the system. This can be pricey and potentially hazardous, but provides the best possible confidence in the system. It may be impossible in situations where deployment system is constantly in use or for other mission critical business applications.If possible, however, live system testing provides a level of confidence is not possible in other approaches. Testing on the live system takes in to account all the particularities of this system without the need to try to replicate that in a check system.It is also common to use capture and playback tools (automated testing). A capture tool is used to record the actions of a typical user to perform a typical task in the system. A player tool is then used to reproduce the action in time of multiple users simultaneously. The multi-user reproduction provides an accurate simulation of the stress of real-world system will come under.The use of tools capture and playback will be used with caution, however. The mere repetition of the exactly the same set of system actions can not constitute adequate proof. Significant amounts of randomisation and variation must be submitted to properly simulate real-world use.It is also necessary to understand the technical architecture of the system. insist on the weakness points, bottlenecks in performance, then their analysis does not prove anything. You need to design Specific tests are performance issues.Having a baseline is also important.Without knowledge of the "pre-change implementation" of application is impossible to assess the impact of any change in performance. "The system can only handle 100 transactions per hour!"comes the cry. But if you only need to handle 50 transactions per hour, is this a problem?Performance testing is difficult, technical, business. The problems that cause performance bottlenecks are often obscure and buried in the code of a database or network. Digging them out requires concerted hard work and directed, disciplined analysis software.
F u n c t i o n a l T e s t i n g
If the aim of a application development project is to "deliver X widget to do & the task", then the aim of"Functional Testing" is to show that X widget actually does the task Y.Simple? Well, not .They are caught by the same ambiguities that lead developers in error. Suppose that the conditions widget specification says "X should do Y", but actually makes widget XY + Z? How do they evaluate Z?Is it necessary? Is it desirable? Do you have other consequences or the original developer holder participation has not considered? Also, how far it coincides with YY was specified by the original set of headline?
Here it may be to see the importance of specifying the precision requirements. If you can not specify them accurately then how can you expect anyone to deliver them accurately or for that matter check reliably?This sounds like common sense, but is much, much harder than anything in the application development life cycle. View my manual on project management for a debat.
Alpha and Beta Testing
There are some commonly recognized milestones in the life cycle of tests.Typically, these milestones are known as alpha and beta. There is no precise definition of what constitute evidence of alpha and beta, but the following are offered as examples of what is commonmeant by these words:Alpha - functionality has been reasonable to permit the firstround (end-to-end) to start testing the process. At this point, the interfacemight not be complete and the process may have lots of errors.Beta - most of the functionality and interface has been completed andremaining work is intended to improve performance, eliminating defects and complete cosmetic work. At this point, there's still lots of flaws, but are
generally well understood.Beta testing is often associated with the first finish user testing.The product is sent to potential customers who have registered their interest in participate in testing the program. Beta testing, however, must be well organizedand otherwise controlled reaction is fragmentary and inconclusive. Care must alsobe taken to ensure that a well prepared prototype is delivered to finish users,otherwise, be disappointed and the time is lost.
White Box testing
White box or glass box testing is based on analysis of the code itself and the internal logic
application and is usually but not exclusively, a developmental task.
Static Analysis and Code Inspection
Static analysis techniques revolve around looking at the source or uncompiled formprogram. They rely on examination of the basic instruction set in its raw form, than as it runs.They are designed to trap semantics & logic errors.Inspection of code is a specific type of static analysis. Use formal & informal reviews to examinelogic & program code structure & source code compare with accepted best practice.In large organizations or mission critical applications, a formal inspection board can be established to ensure that program written meets the maximum standards required. In less official inspections development manager can perform this task, or even a peer.Inspection code can also be automated. Plenty of of syntax & style of the ladies that exist today to verify that a code module meets definite pre-defined rules. Through the implementation of an automated correction
through code, it is easy to verify conformity to standards-based & highlight areas that need human attention.A variant of the code inspection is the use of peer programs as called for in the methodologies & the Extreme Programming (XP). In pair programming XP, code modules are shared between fourindividuals. As a person writes a section of code the other reviews & evaluates the code quality. Critic looks for defects in the logic, lapses of coding standards & evil practice. The functions are then exchanged. Proponents say this is a fast way to accomplish lovely code quality & critics contend that its a lovely way to lose a lot of people's time.As for me, the jury is still out.
Dynamic Analysis
While static analysis examines the source code in its RAW format, dynamic analysis is seen in thecompiled / interpreted code while running in the right environment. Normally this is analysis of varying amounts such as memory usage, processor usage or overall performance.A common form of dynamic analysis used is the analysis of memory. Since memory and Pointer errors are most of the defects found in program programs, analysis of memory is useful. A typical analyzer memory reports in the current level of memory usage of a program under check and the readiness of that memory. The developer can then "modify" or optimize the memory usage of the program to ensure the best performance and most robust memory management.Often this is done by "implementing" the code. A copy of the source code is passed to the dynamicanalysis device that inserts function calls to external code libraries. These calls then run the export
time data in the source program for an analysis device. The analysis device can then program the profile while it is running. Often, these tools are used in conjunction with other automated toolssimulate actual conditions for the program under check. Up by ramps on the program or through the implementation of typical input data, the use of program memory and other resources can be adequately profile under real world conditions.
Unit, Integration and System testing
The first type of tests that can be done at any stage of development is testing the unit.In this sense, the discrete components of the final product are assessed separately before being assembledin to larger units. The units are normally tested through the use of "test harness" that simulate thecontext in which the unit will be integrated. The check tool provides some of knowninputs & performance measures of the unit under check, which are then compared with a forecast of values to choose if there's problems.In integration testing smaller units are integrated in to larger units & larger units in the overall technique. This differs from the unit where the units are no longer tested independently, but ingroups, changing the emphasis on individual units to the interaction between them.At this point, "Outline" & "drivers" to take over from the check harness.A stub is a simulation of a sub-unit that can be used to simulate the unit in a largerAssembly. For example, if the units A, B & C constitute the main elements of the D drive then the generalAssembly could be tested by the assembly of units A & B & a simulation of C if C is not complete. Similarly, if the D drive was not complete in itself could be represented by a driver "or the simulation of super-unit.Since successive areas of functionality have been done can be evaluated & incorporated in to the overall project. Without the integration check is limited to testing fully assembled product or technique that is inefficient & error prone. Much better to check the building blocks as go & build your project from the beginning of a series of controlled steps.Technique testing is the rehearsal of a application product assembly. Testing Systems is important because it is only at this stage that the complexity of the product is present. The focus on check systems is typically to ensure that the product correctly answered all possible input conditions & (importantly) the product handles exceptions in a controlled & acceptable manner. Technique testing is often more formal stage of testing & more structured.The SIT or Check Team In huge organizations it is common to find a "SIT" or independent check team. SIT usually means"Systems Integration Test" or "Implementation of Check Systems" or possibly "save, check!"& it is the role of the unit of equipment, technique testing or integration testing? Well, nobody knows. The SIT team's role is usually not unity, integration & technique check, but a combination of all five. Are expected to participate in unit testing with developers to carryover out the integration of units in huge components, as well as giving Finish to finish testing of systems.

Since successive areas of functionality have been done can be evaluated & incorporated in to theoverall project. Without the integration check is limited to testing fully assembled product or technique that is inefficient & error prone. Much better to check the building blocks as go & build your project from the beginning of a series of controlled steps.Technique testing is the rehearsal of a application product assembly. Testing Systems
is important because it is only at this stage that the complexity of the product is present. The focus on check systems is typically to ensure that the product correctly answered all possible input conditions & (importantly) the product handles exceptions in a controlled & acceptable manner. Technique testing is often more formal stage of testing & more structured.
The SIT or Check Team
In gigantic organizations it is common to find a "SIT" or independent check team. SIT usually means"Systems Integration Test" or "Implementation of Check Systems" or possibly "save, check!"& it is the role of the unit of equipment, technique testing or integration testing? Well, nobody knows. The SIT team's role is usually not unity, integration & technique check, but a combination of all three. Are expected to participate in unit testing with developers to carryover out the integration of units in gigantic components, as well as giving Finish to finish testing of systems.Sometimes the expectation is that the SIT team will become the companies Quality Assurance team, although they have no direct influence on the application is developed. The coursework is that increasing the period & rigor of the evidence that will improve the quality of the products released - & he does.But it does nothing to improve the quality of construction products - so it is not quality.
In the best of worlds, this team can act as an agent of change. You can introduce measures & processes that prevent defects from being written in the code in the first place because they may working with development teams to identify areas that need fixing, & can highlight the success improvements in development processes.In the worst of all worlds of the pressure in the application development units more & more projects with extended check cycles in the gigantic number of defects are found, & project schedules slip. The check equipment attracts find fault & blame for long check cycles, & nobody knows how to solve the problem.
Acceptance Testing
Projects large-scale application often have a final phase of the check called "acceptance testing".Acceptance testing is an important phase & clearly separated from the previous testing efforts& aims to ensure that the product meets the maximum standards of quality before theiris accepted by the customer or client.This is where somebody has to sign the check.Often, the customer will have their finish users to perform testing to verify the application wasout to your satisfaction (this is called "user acceptance testing" or "UAT"). Often UATtesting processes outside the application itself to ensure that the entire solution works as advertised.While the way of other forms of evidence can be more "free", the acceptance testing phase should representof a planned series of tests & procedures to ensure the release of exit from the production stagereaches the finish user in an optimum state, as free as humanly possible defects.Acceptance tests, in theory, should also be fast & relatively painless. The earlier phases of the check are devoid of all the issues & this should be a formality. In immature application development,acceptance testing becomes a trap for the latest issues, reloading the project with the risk.The general acceptance check, also focuses on objects outside the application itself. Three solution oftenhas lots of elements outside the application itself. These may include: manual & documentation, process changes, training materials, operational procedures, operational performance measures (SLA).
These are not usually tested at earlier stages of the tests that focus on the functional aspects of the application itself. However, the realization of these other elements is important for the success of thethe solution as a whole. Generally are not evaluated until the application is complete because that need a fully functional piece of application with its new workflows & new data needs to assess.
Test Automation :
Organizations often try to reduce the cost of testing. Most organizations do not feel comfortable with reducing the amount of testing so in lieu look at improving the efficiency of testing. Fortunately,There's a quantity of application vendors who claim to be able to do exactly that! Offer Automated tools have a check case, automate and execute against a target repeatedly application.Music to the ears of management!
However, there's some myths about automated check tools that must be dispelled:
Automated check finds no more errors of manual testing - a manual tester with experience who is familiar with the process is more flawed than a new set of automated tests.
Automation does not solve the development process - as hard as it seems, the testers do not generate defects, developers do. Automated testing does not improve the development process although it may highlight a quantity of the issues.
Automated testing is not necessarily faster - the initial work of check automation is much more higher than the performance of a manual check, so it will take longer and cost more to check the firsttime.
Automation only pay over time. It will also cost more to maintain. Not everything has to be automated - some things do not lend themselves to automation,Some systems change speedy for automation, the evidence of benefit from partial automation --has to be selective about what they automate to reap the benefits.
The Hidden Cost:
The hidden cost of check automation in their maintenance.An automated check assets that can be written two times & run often pays for itself much more faster than two that has to be constantly rewritten to keep pace with the application & therein lies the problem.Automation tools, like any other piece of application, check with the application under check through a interface. If the interface is changing all the time so no matter what vendors say, the evidence have to alter . Moreover, if the interfaces remain constant, but the underlying code changes & then continue walking the functional tests & (hopefully) still find bugs.Plenty of application projects do not have stable interfaces. The user interface face (or GUI) is actually the
further alter area because it is the users tiny more. Trying to automate testing Two piece of application that has a rapidly evolving interface is a bit like trying to define a jellyfish wall.
What is Automated Testing Good For?
Automated testing is nice at:
• Load and performance testing - automated tests are a prerequisite of conducting load and performance testing. You can not have 300 users by hand check technique simultaneously, it should be automated.
• Evidence of smoke - a speedy and dirty check to confirm that the technique "basically" work. A technique that fails the smoke check is automatically sent back to the previous stage, the work is completed, saving time and hard work
• Regression testing - functional testing should not be changed in a stream code release. Existing automated tests can be run and which will highlight changes in functionality that are designed to check (in incremental Development versions can be tested and returned to work quickly if they have altered functionality delivered in previous increments)
• Configuration of check information or pre-test conditions - an automated check can be used to put to the check information or check conditions that would otherwise be time
• repetitive testing, which includes the manual tasks are tedious and liable to human error (for example, checking account balances to 7 decimal.
Pitfalls of Test Automation:
Automating your check should be treated as a application project in its own right.It should clearly define their needs. You must specify what will be automated & what is not. It must design a solution for testing & that the solution must be validated against an external reference.Consider the situation where a piece of application is written in a functional specification error.Then take a check of the functional specification. & write an automated check it.Does the code pass the check?Of work. Every time.Does the application get the result the customer wants? It proves to be valid?Nope.Of work, manual testing may fall in to the same trap. But the manual check involves human testers making impertinent questions & provoke debate. Automated check only do what they say.
If you tell them to do something wrong, they won't ask questions.In addition, automated tests must be designed with maintenance in mind. They must be built modular units should be designed to be flexible & driven parameters (non-coding constant). Must follow strict coding standards & should be a review method to ensure the rules are applied.Failure to do this will result in the generation of a code base that is difficult to maintain, incorrect in their assumptions & that decay faster than code that is supposed to be the check.
Here it may be to see the importance of specifying the precision requirements. If you can not specify them accurately then how can you expect anyone to deliver them accurately or for that matter check reliably?This sounds like common sense, but is much, much harder than anything in the application development life cycle. View my manual on project management for a debat.
Alpha and Beta Testing
There are some commonly recognized milestones in the life cycle of tests.Typically, these milestones are known as alpha and beta. There is no precise definition of what constitute evidence of alpha and beta, but the following are offered as examples of what is commonmeant by these words:Alpha - functionality has been reasonable to permit the firstround (end-to-end) to start testing the process. At this point, the interfacemight not be complete and the process may have lots of errors.Beta - most of the functionality and interface has been completed andremaining work is intended to improve performance, eliminating defects and complete cosmetic work. At this point, there's still lots of flaws, but are
generally well understood.Beta testing is often associated with the first finish user testing.The product is sent to potential customers who have registered their interest in participate in testing the program. Beta testing, however, must be well organizedand otherwise controlled reaction is fragmentary and inconclusive. Care must alsobe taken to ensure that a well prepared prototype is delivered to finish users,otherwise, be disappointed and the time is lost.
White Box testing
White box or glass box testing is based on analysis of the code itself and the internal logic
application and is usually but not exclusively, a developmental task.
Static Analysis and Code Inspection
Static analysis techniques revolve around looking at the source or uncompiled formprogram. They rely on examination of the basic instruction set in its raw form, than as it runs.They are designed to trap semantics & logic errors.Inspection of code is a specific type of static analysis. Use formal & informal reviews to examinelogic & program code structure & source code compare with accepted best practice.In large organizations or mission critical applications, a formal inspection board can be established to ensure that program written meets the maximum standards required. In less official inspections development manager can perform this task, or even a peer.Inspection code can also be automated. Plenty of of syntax & style of the ladies that exist today to verify that a code module meets definite pre-defined rules. Through the implementation of an automated correction
through code, it is easy to verify conformity to standards-based & highlight areas that need human attention.A variant of the code inspection is the use of peer programs as called for in the methodologies & the Extreme Programming (XP). In pair programming XP, code modules are shared between fourindividuals. As a person writes a section of code the other reviews & evaluates the code quality. Critic looks for defects in the logic, lapses of coding standards & evil practice. The functions are then exchanged. Proponents say this is a fast way to accomplish lovely code quality & critics contend that its a lovely way to lose a lot of people's time.As for me, the jury is still out.
Dynamic Analysis
While static analysis examines the source code in its RAW format, dynamic analysis is seen in thecompiled / interpreted code while running in the right environment. Normally this is analysis of varying amounts such as memory usage, processor usage or overall performance.A common form of dynamic analysis used is the analysis of memory. Since memory and Pointer errors are most of the defects found in program programs, analysis of memory is useful. A typical analyzer memory reports in the current level of memory usage of a program under check and the readiness of that memory. The developer can then "modify" or optimize the memory usage of the program to ensure the best performance and most robust memory management.Often this is done by "implementing" the code. A copy of the source code is passed to the dynamicanalysis device that inserts function calls to external code libraries. These calls then run the export
time data in the source program for an analysis device. The analysis device can then program the profile while it is running. Often, these tools are used in conjunction with other automated toolssimulate actual conditions for the program under check. Up by ramps on the program or through the implementation of typical input data, the use of program memory and other resources can be adequately profile under real world conditions.
Unit, Integration and System testing
The first type of tests that can be done at any stage of development is testing the unit.In this sense, the discrete components of the final product are assessed separately before being assembledin to larger units. The units are normally tested through the use of "test harness" that simulate thecontext in which the unit will be integrated. The check tool provides some of knowninputs & performance measures of the unit under check, which are then compared with a forecast of values to choose if there's problems.In integration testing smaller units are integrated in to larger units & larger units in the overall technique. This differs from the unit where the units are no longer tested independently, but ingroups, changing the emphasis on individual units to the interaction between them.At this point, "Outline" & "drivers" to take over from the check harness.A stub is a simulation of a sub-unit that can be used to simulate the unit in a largerAssembly. For example, if the units A, B & C constitute the main elements of the D drive then the generalAssembly could be tested by the assembly of units A & B & a simulation of C if C is not complete. Similarly, if the D drive was not complete in itself could be represented by a driver "or the simulation of super-unit.Since successive areas of functionality have been done can be evaluated & incorporated in to the overall project. Without the integration check is limited to testing fully assembled product or technique that is inefficient & error prone. Much better to check the building blocks as go & build your project from the beginning of a series of controlled steps.Technique testing is the rehearsal of a application product assembly. Testing Systems is important because it is only at this stage that the complexity of the product is present. The focus on check systems is typically to ensure that the product correctly answered all possible input conditions & (importantly) the product handles exceptions in a controlled & acceptable manner. Technique testing is often more formal stage of testing & more structured.The SIT or Check Team In huge organizations it is common to find a "SIT" or independent check team. SIT usually means"Systems Integration Test" or "Implementation of Check Systems" or possibly "save, check!"& it is the role of the unit of equipment, technique testing or integration testing? Well, nobody knows. The SIT team's role is usually not unity, integration & technique check, but a combination of all five. Are expected to participate in unit testing with developers to carryover out the integration of units in huge components, as well as giving Finish to finish testing of systems.

is important because it is only at this stage that the complexity of the product is present. The focus on check systems is typically to ensure that the product correctly answered all possible input conditions & (importantly) the product handles exceptions in a controlled & acceptable manner. Technique testing is often more formal stage of testing & more structured.
The SIT or Check Team
In gigantic organizations it is common to find a "SIT" or independent check team. SIT usually means"Systems Integration Test" or "Implementation of Check Systems" or possibly "save, check!"& it is the role of the unit of equipment, technique testing or integration testing? Well, nobody knows. The SIT team's role is usually not unity, integration & technique check, but a combination of all three. Are expected to participate in unit testing with developers to carryover out the integration of units in gigantic components, as well as giving Finish to finish testing of systems.Sometimes the expectation is that the SIT team will become the companies Quality Assurance team, although they have no direct influence on the application is developed. The coursework is that increasing the period & rigor of the evidence that will improve the quality of the products released - & he does.But it does nothing to improve the quality of construction products - so it is not quality.
In the best of worlds, this team can act as an agent of change. You can introduce measures & processes that prevent defects from being written in the code in the first place because they may working with development teams to identify areas that need fixing, & can highlight the success improvements in development processes.In the worst of all worlds of the pressure in the application development units more & more projects with extended check cycles in the gigantic number of defects are found, & project schedules slip. The check equipment attracts find fault & blame for long check cycles, & nobody knows how to solve the problem.
Acceptance Testing
Projects large-scale application often have a final phase of the check called "acceptance testing".Acceptance testing is an important phase & clearly separated from the previous testing efforts& aims to ensure that the product meets the maximum standards of quality before theiris accepted by the customer or client.This is where somebody has to sign the check.Often, the customer will have their finish users to perform testing to verify the application wasout to your satisfaction (this is called "user acceptance testing" or "UAT"). Often UATtesting processes outside the application itself to ensure that the entire solution works as advertised.While the way of other forms of evidence can be more "free", the acceptance testing phase should representof a planned series of tests & procedures to ensure the release of exit from the production stagereaches the finish user in an optimum state, as free as humanly possible defects.Acceptance tests, in theory, should also be fast & relatively painless. The earlier phases of the check are devoid of all the issues & this should be a formality. In immature application development,acceptance testing becomes a trap for the latest issues, reloading the project with the risk.The general acceptance check, also focuses on objects outside the application itself. Three solution oftenhas lots of elements outside the application itself. These may include: manual & documentation, process changes, training materials, operational procedures, operational performance measures (SLA).
These are not usually tested at earlier stages of the tests that focus on the functional aspects of the application itself. However, the realization of these other elements is important for the success of thethe solution as a whole. Generally are not evaluated until the application is complete because that need a fully functional piece of application with its new workflows & new data needs to assess.
Test Automation :
Organizations often try to reduce the cost of testing. Most organizations do not feel comfortable with reducing the amount of testing so in lieu look at improving the efficiency of testing. Fortunately,There's a quantity of application vendors who claim to be able to do exactly that! Offer Automated tools have a check case, automate and execute against a target repeatedly application.Music to the ears of management!
However, there's some myths about automated check tools that must be dispelled:
Automated check finds no more errors of manual testing - a manual tester with experience who is familiar with the process is more flawed than a new set of automated tests.
Automation does not solve the development process - as hard as it seems, the testers do not generate defects, developers do. Automated testing does not improve the development process although it may highlight a quantity of the issues.
Automated testing is not necessarily faster - the initial work of check automation is much more higher than the performance of a manual check, so it will take longer and cost more to check the firsttime.
Automation only pay over time. It will also cost more to maintain. Not everything has to be automated - some things do not lend themselves to automation,Some systems change speedy for automation, the evidence of benefit from partial automation --has to be selective about what they automate to reap the benefits.
The Hidden Cost:
The hidden cost of check automation in their maintenance.An automated check assets that can be written two times & run often pays for itself much more faster than two that has to be constantly rewritten to keep pace with the application & therein lies the problem.Automation tools, like any other piece of application, check with the application under check through a interface. If the interface is changing all the time so no matter what vendors say, the evidence have to alter . Moreover, if the interfaces remain constant, but the underlying code changes & then continue walking the functional tests & (hopefully) still find bugs.Plenty of application projects do not have stable interfaces. The user interface face (or GUI) is actually the
further alter area because it is the users tiny more. Trying to automate testing Two piece of application that has a rapidly evolving interface is a bit like trying to define a jellyfish wall.
What is Automated Testing Good For?
Automated testing is nice at:
• Load and performance testing - automated tests are a prerequisite of conducting load and performance testing. You can not have 300 users by hand check technique simultaneously, it should be automated.
• Evidence of smoke - a speedy and dirty check to confirm that the technique "basically" work. A technique that fails the smoke check is automatically sent back to the previous stage, the work is completed, saving time and hard work
• Regression testing - functional testing should not be changed in a stream code release. Existing automated tests can be run and which will highlight changes in functionality that are designed to check (in incremental Development versions can be tested and returned to work quickly if they have altered functionality delivered in previous increments)
• Configuration of check information or pre-test conditions - an automated check can be used to put to the check information or check conditions that would otherwise be time
• repetitive testing, which includes the manual tasks are tedious and liable to human error (for example, checking account balances to 7 decimal.
Pitfalls of Test Automation:
Automating your check should be treated as a application project in its own right.It should clearly define their needs. You must specify what will be automated & what is not. It must design a solution for testing & that the solution must be validated against an external reference.Consider the situation where a piece of application is written in a functional specification error.Then take a check of the functional specification. & write an automated check it.Does the code pass the check?Of work. Every time.Does the application get the result the customer wants? It proves to be valid?Nope.Of work, manual testing may fall in to the same trap. But the manual check involves human testers making impertinent questions & provoke debate. Automated check only do what they say.
If you tell them to do something wrong, they won't ask questions.In addition, automated tests must be designed with maintenance in mind. They must be built modular units should be designed to be flexible & driven parameters (non-coding constant). Must follow strict coding standards & should be a review method to ensure the rules are applied.Failure to do this will result in the generation of a code base that is difficult to maintain, incorrect in their assumptions & that decay faster than code that is supposed to be the check.
The Testing Mindset
No particular philosophy attached to "evidence of good".A professional tester comes to a product with the attitude that the product is broken - youhas shortcomings, and it is your job to discover them. They assume the product or technique is intrinsicallyfaults and his job is to "illuminate" the faults.This approach is necessary in testing.The designers and application developers with a focus on optimism based on the assumption that thethe changes they make are the right solution to a particular problem. But they are that --assumptions Without being shown that there's over guesses correctly. Developers often overlook ambiguities in the fundamental requirements in order to complete the project, or do not recognizewhen they see them. These ambiguities are then incorporated in to the code and represent a defectcompared with the finish user needs.By adopting a skeptical approach, the tester provides a balance.The tester takes nothing at face value. The tester always the query "why?" They seekexpel security where none exists. They seek to illuminate the darkest part of the draftwith the light of the investigation.Sometimes this attitude can bring conflicts with developers and designers. But developers anddesigners can also be testers! If you can adopt this way of thinking of some part of the project,they can offer that the critical assessment that is so vital to a balanced draft. Recognizing the need forthis thinking is the first step towards a successful check.
Test Early Test Often
There is an oft-quoted axiom of program engineering that states - "found an error in design timecosts ten times less to fix in the coding of a hundred times less than those found afterlaunch. "Barry Boehm, the creator of this idea, actually cites 1:6:10:1000 proportions of costserror in setting requirements, design, coding & implementation phases.If you find errors, start as soon as possible.This means that the unit tests (qqv) for developers, integration testing during assembly & techniquetrials - in that order of priority! Tenant is a well understood program development thatbasically ignored by most program development efforts.Nor is it one step from the evidence.His last first check basically identifies where the defects are. At least, a second step of(post-fix) requires the check to verify that defects have been resolved. With the passage of the tests
you make more confident & should see their convergence projecton the date of delivery. As usually passed no fewer than one tests at any stage isinsufficient.
Regression vs. Retesting
You should repeat the check arrangements to ensure that issues are resolved before development can progress.Therefore, further testing is the act of repeating a check to verify that a defect found has been correctly identified.Regression testing on the other hand is the act of repetition of tests in "parallel" to ensure the areasthat the solution applied or a code change has made no other errors or unexpected behavior.For example, if an error is detected in a particular file handling system can then be correctedby a simple change of code. If that code, however, is used in some of different placesall program, the effects of such change could be difficult to anticipate. What seemsto be a minor detail could affect a separate module of code in the rest of the program. A corrigendum In fact two could introduce errors elsewhere.You may be surprised to know how common this is. In empirical studies haveestimated that up to 50% correction of factual errors introduce additional errors in the code. Given this,it is a
wonder that any program project makes its timely delivery.Better quality control processes will reduce this ratio but not eliminate it. Developers of riskmake occasional errors every time they place their hands on the keyboard. An accidental slia code that replaces a point with a comma, can not be detected for weeks, but could have serious repercussions.Regression testing attempts to mitigate this problem by assessing the "impact zone" affected by achange or correct a mistake to see if it's unintended consequences. Check known lovely behaviorafter a change.It is common for regression testing to cover the entire product or program under check.Why? Because programmers are very bad for being able to track & control change in theirprogram. When a problem that will cause other problems. Usually have no ideathe impact of a change will, nor can they reliably support making these changes.If developers can, with certainty, specify the exact scope & impact of a change they made thentests could be confined to the
affeced area. Oh tester that makes such an assumption however!
White-Box vs Black-Box testing
Evidence of done units of functional code that is known as black box testing because testers treatobject as a black box. They are concerned with the verification of specified input against expectedproduction & not worry about the logic of what happens in between.User Acceptance Testing (UAT) & testing systems are the classic example of black-box testing.White box or glass box testing is based on analysis of the code itself & the internal logic
application. White box testing is often but not always, the competition from programmers. Usetechniques ranging from highly technical or specific testing technology through such things ascode inspections.Although white-box techniques can be used at any stage of the life cycle of a application product that tend to be found in the activities of unit testing.
Verification and Validation
Testers often make the mistake of not keeping an eye on the objective. Narrow its focusto the next phase of application development and lose sight of the bigger picture.The verification tasks are designed to ensure the product is internally consistent. They ensure that the product meets the specification, the specification meets the requirements.and so on.Most of the testing tasks are the investigation - with the final product being tested against somereference rate to ensure the output is as expected.For example, the check designs are usually written requirements documents and specification. This verifies that the application provides the technical requirements of requirements and specifications.However, not against the "correctness" of the requirement!In a large scale project that I worked as a check director, complained to the development teamour documentation was out of date and they were having difficulty constructing valid tests. They grumbled, but finally they said it would update the specifications and provide us with a new version plan our tests.When I arrived the next day, I met two programmers sitting at a computer terminal pair. While two of them ran the latest version of the application, another glance over his shoulder and then write the display behavior of the product as the latest version of the specification!When they complain to the development manager, said "What?" The specification is up As of today, no? "The customer, however, was not amused, they now had no way of determining what the program is supposed to deal with what actually did.The validation tasks are as important as testing, but less common.Validation is the use of external sources of reference to ensure that the internal design is valid, I. e.meets the expectations of users. Using external references (such as the direct involvement of finish users)the check team can validate the design decisions and ensure that the project goes in to the correctaddress. Usability testing is an excellent example of a useful validation method.A note on the V-model "There is a check model application program called V-model, but I won't reproduce here because Iis a dreadful model. It illustrates the different phases of the SDLC testing, matching in a check phaseto a phase of requirements / design.I do not like because it emphasizes the verification work on the validation tasks.Like the waterfall model which is based on each stage from perfect and ultimately, only error detectionthe finish of the cycle. And like the waterfall model is an updated version attempts to correct this, but only serves to muddy the waters.But the V-model illustrates the importance of different levels of testing at different stages of theproject. I leave as an exercise for the reader to uncover it.
Test Early Test Often
There is an oft-quoted axiom of program engineering that states - "found an error in design timecosts ten times less to fix in the coding of a hundred times less than those found afterlaunch. "Barry Boehm, the creator of this idea, actually cites 1:6:10:1000 proportions of costserror in setting requirements, design, coding & implementation phases.If you find errors, start as soon as possible.This means that the unit tests (qqv) for developers, integration testing during assembly & techniquetrials - in that order of priority! Tenant is a well understood program development thatbasically ignored by most program development efforts.Nor is it one step from the evidence.His last first check basically identifies where the defects are. At least, a second step of(post-fix) requires the check to verify that defects have been resolved. With the passage of the tests
you make more confident & should see their convergence projecton the date of delivery. As usually passed no fewer than one tests at any stage isinsufficient.
Regression vs. Retesting
You should repeat the check arrangements to ensure that issues are resolved before development can progress.Therefore, further testing is the act of repeating a check to verify that a defect found has been correctly identified.Regression testing on the other hand is the act of repetition of tests in "parallel" to ensure the areasthat the solution applied or a code change has made no other errors or unexpected behavior.For example, if an error is detected in a particular file handling system can then be correctedby a simple change of code. If that code, however, is used in some of different placesall program, the effects of such change could be difficult to anticipate. What seemsto be a minor detail could affect a separate module of code in the rest of the program. A corrigendum In fact two could introduce errors elsewhere.You may be surprised to know how common this is. In empirical studies haveestimated that up to 50% correction of factual errors introduce additional errors in the code. Given this,it is a
wonder that any program project makes its timely delivery.Better quality control processes will reduce this ratio but not eliminate it. Developers of riskmake occasional errors every time they place their hands on the keyboard. An accidental slia code that replaces a point with a comma, can not be detected for weeks, but could have serious repercussions.Regression testing attempts to mitigate this problem by assessing the "impact zone" affected by achange or correct a mistake to see if it's unintended consequences. Check known lovely behaviorafter a change.It is common for regression testing to cover the entire product or program under check.Why? Because programmers are very bad for being able to track & control change in theirprogram. When a problem that will cause other problems. Usually have no ideathe impact of a change will, nor can they reliably support making these changes.If developers can, with certainty, specify the exact scope & impact of a change they made thentests could be confined to the
affeced area. Oh tester that makes such an assumption however!
White-Box vs Black-Box testing
Evidence of done units of functional code that is known as black box testing because testers treatobject as a black box. They are concerned with the verification of specified input against expectedproduction & not worry about the logic of what happens in between.User Acceptance Testing (UAT) & testing systems are the classic example of black-box testing.White box or glass box testing is based on analysis of the code itself & the internal logic
application. White box testing is often but not always, the competition from programmers. Usetechniques ranging from highly technical or specific testing technology through such things ascode inspections.Although white-box techniques can be used at any stage of the life cycle of a application product that tend to be found in the activities of unit testing.
Verification and Validation
Testers often make the mistake of not keeping an eye on the objective. Narrow its focusto the next phase of application development and lose sight of the bigger picture.The verification tasks are designed to ensure the product is internally consistent. They ensure that the product meets the specification, the specification meets the requirements.and so on.Most of the testing tasks are the investigation - with the final product being tested against somereference rate to ensure the output is as expected.For example, the check designs are usually written requirements documents and specification. This verifies that the application provides the technical requirements of requirements and specifications.However, not against the "correctness" of the requirement!In a large scale project that I worked as a check director, complained to the development teamour documentation was out of date and they were having difficulty constructing valid tests. They grumbled, but finally they said it would update the specifications and provide us with a new version plan our tests.When I arrived the next day, I met two programmers sitting at a computer terminal pair. While two of them ran the latest version of the application, another glance over his shoulder and then write the display behavior of the product as the latest version of the specification!When they complain to the development manager, said "What?" The specification is up As of today, no? "The customer, however, was not amused, they now had no way of determining what the program is supposed to deal with what actually did.The validation tasks are as important as testing, but less common.Validation is the use of external sources of reference to ensure that the internal design is valid, I. e.meets the expectations of users. Using external references (such as the direct involvement of finish users)the check team can validate the design decisions and ensure that the project goes in to the correctaddress. Usability testing is an excellent example of a useful validation method.A note on the V-model "There is a check model application program called V-model, but I won't reproduce here because Iis a dreadful model. It illustrates the different phases of the SDLC testing, matching in a check phaseto a phase of requirements / design.I do not like because it emphasizes the verification work on the validation tasks.Like the waterfall model which is based on each stage from perfect and ultimately, only error detectionthe finish of the cycle. And like the waterfall model is an updated version attempts to correct this, but only serves to muddy the waters.But the V-model illustrates the importance of different levels of testing at different stages of theproject. I leave as an exercise for the reader to uncover it.
Testing in the Software Development Life Cycle
The aim of testing is to reduce risk.Unknown factors in the development and design of new application can derail a project andminor risks may be delayed. By using a check cycle and the resolution can identify the level of risk,make informed decisions and ultimately, reduce uncertainty and eliminate errors.The check is the only device in the arsenal of development, which reduces defects. Planning, design and quality controlcan reduce the number of defects that fall in to a product, but can not eliminate those who arealready there. And any type of encoding will introduce more errors, since it involves changingsomething of a known nice state to a state unknown, unproved.Ideally, testing should be conducted throughout the development life cycle. Most of the time (as inthe waterfall model) is basically stuck in the back. If the purpose of testing is to reducerisk, this means accumulating risk throughout the project to solve the final - in itself a risky tactic.Could it be that this is a valid approach. By allowing developers to focus on building applicationcomponents and then at a later date, the alter to the rectification of the issues allowedpartition their efforts and focus on three type of task at a time.But as the gap between development and the resolution increases so does the complexity of the solutionissues (see "first check, check often" on nextc hapter). In any reasonably giant application development project delay is long. To better disseminate the various phases of testing throughoutlifecycle to detect errors as soon as possible.
Traceability
Another function of the check is (curiously) to confirm what has been delivered.Given a complex project with hundreds or perhaps thousands of game holder requirements, how does that have implemented them all? How to try during yourtests or launch a particular requirement has been met? How can you track the progress delivery of a particular requirement during development?This is the problem of traceability.How does a map requirement of a design element (in the technical specification, for example)and how that map to an element of code that implements this check and how to mapdemonstrate that it's correctly applied?In a simple project is sufficient to construct a table that is out. In a giant scale project ofextensive requirements to overwhelm such traceability. It is also possible that a singlerequirement is met multiple elements in the design or a single element in thedesign satisfies multiple requirements. This makes the tracking reference number difficult.If you require a better solution, I would suggest an integrated technique to track the requirements for you.There outside the platform has tools that use databases to track the requirements. These are thenrelated to similar specifications and tools to provide as traceability. A technique like this canautomatically produces reports that highlight the requirements are not delivered or not tested. These systemsalso be associated with SCM (Application Configuration Management) and can be veryexpensive, depending on the level of functionality.See the section on "change management" for a discussion of these systems.
Traceability
Another function of the check is (curiously) to confirm what has been delivered.Given a complex project with hundreds or perhaps thousands of game holder requirements, how does that have implemented them all? How to try during yourtests or launch a particular requirement has been met? How can you track the progress delivery of a particular requirement during development?This is the problem of traceability.How does a map requirement of a design element (in the technical specification, for example)and how that map to an element of code that implements this check and how to mapdemonstrate that it's correctly applied?In a simple project is sufficient to construct a table that is out. In a giant scale project ofextensive requirements to overwhelm such traceability. It is also possible that a singlerequirement is met multiple elements in the design or a single element in thedesign satisfies multiple requirements. This makes the tracking reference number difficult.If you require a better solution, I would suggest an integrated technique to track the requirements for you.There outside the platform has tools that use databases to track the requirements. These are thenrelated to similar specifications and tools to provide as traceability. A technique like this canautomatically produces reports that highlight the requirements are not delivered or not tested. These systemsalso be associated with SCM (Application Configuration Management) and can be veryexpensive, depending on the level of functionality.See the section on "change management" for a discussion of these systems.
Different Models of Software Development
The Waterfall Model
Doing something can be thought of as a linear sequence of events. It starts in A, B & doesthen go to C & finally ending in Z. This is simplistic, but allows display the series of events in the simplest form & emphasize the importance of delivering theme asures taken to a conclusion.Below is the "Waterfall Model", which shows the typical developmental tasks that flow in to them.
Early in the history of program development
Doing something can be thought of as a linear sequence of events. It starts in A, B & doesthen go to C & finally ending in Z. This is simplistic, but allows display the series of events in the simplest form & emphasize the importance of delivering theme asures taken to a conclusion.Below is the "Waterfall Model", which shows the typical developmental tasks that flow in to them.
Early in the history of program development
The Need for Testing
My favorite line in the program, Bruce Sterling, The Hacker Crackdown "-- The things they call "software" is not like anything that human society is used to think.The program is like a machine, & something like mathematics, & something like language& something like thought & art, & information but program is not, in fact, none of the otherthings. The protein quality of program is a major source of its fascination. It also makes program very powerful, very subtle, very unpredictable & very dangerous.Some program is bad & buggy.
Getting started with Manual testing
Manual Testing : It is basically the appraoch to test the software whether its functioning well or not.
Testing can never completely identify all the defects within software. Instead, it furnishes a criticism or comparison that compares the state and behavior of the product .Every software product has a target audience. For example, the audience for mobile software is completely different from banking software. Therefore, when an organization develops or otherwise invests in a software product, it can assess whether the software product will be acceptable to its end users, its target audience, its purchasers, and other stakeholders.
Testing can never completely identify all the defects within software. Instead, it furnishes a criticism or comparison that compares the state and behavior of the product .Every software product has a target audience. For example, the audience for mobile software is completely different from banking software. Therefore, when an organization develops or otherwise invests in a software product, it can assess whether the software product will be acceptable to its end users, its target audience, its purchasers, and other stakeholders.
Subscribe to:
Posts (Atom)